이번 포스팅에서는 Spark를 Windows 10 로컬에 세팅하여 vscode에서 활용하는 방법을 알려드립니다.
자바 설치
cmd 창에 아래와 같이 출력이 있어야 하며 없으면 JAVA를 설치해 주어야함.
> java -version
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Download the Latest Java LTS Free
Subscribe to Java SE and get the most comprehensive Java support available, with 24/7 global access to the experts.
www.oracle.com
2. 자바 환경변수 세팅
운영체제 어디에서든지 자바를 인식할 수 있도록 하기 위해 환경변수 세팅이 필요
1) 제어판의 "시스템 환경 변수 실행"
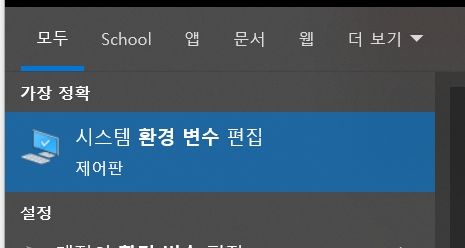
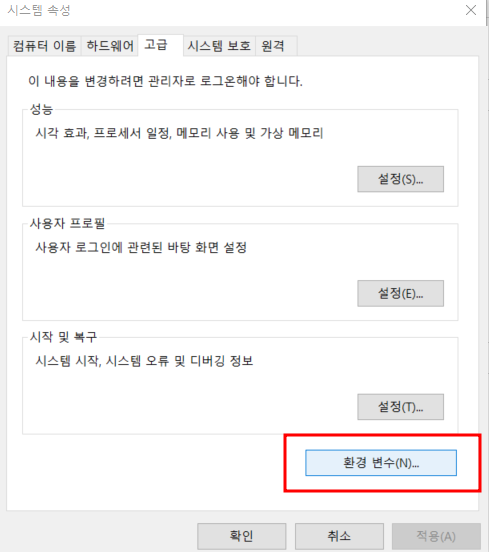
2) 환경변수 선택
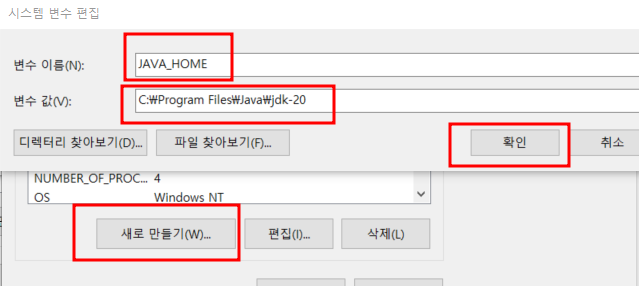
3) JAVA_HOME 경로 세팅
- 새로만들기 클릭
- 변수이름 : JAVA_HOME
- 변수값 : C:\Program Files\Java\jdk-20 (java가 설치된 경로)
- 확인 클릭
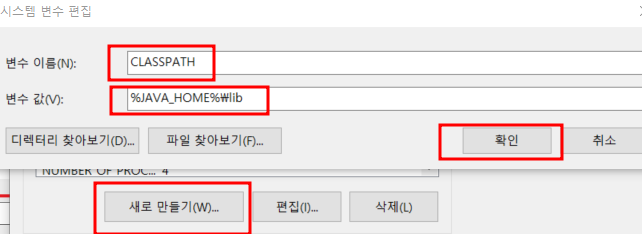
4) CLASSPATH 경로 세팅
- 새로만들기 클릭
- 변수이름 : CLASSPATH
- 변수값 : %JAVA_HOME%\lib
- 확인 클릭
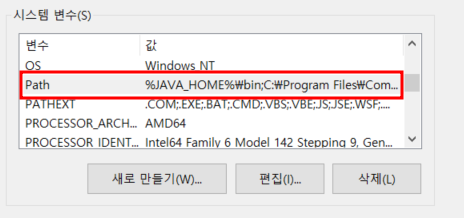
5) path에 자바 경로 세팅
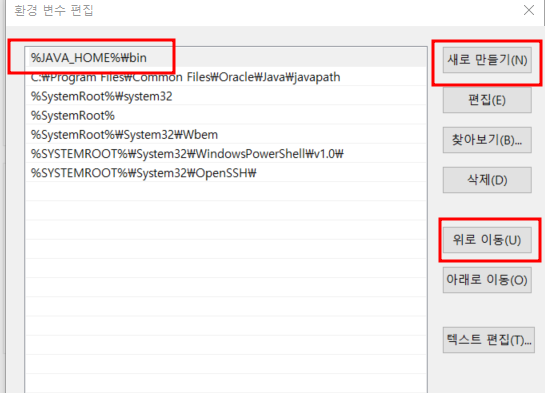
- path를 더블클릭
- 새로만들기 클릭
- %JAVA_HOME%\bin 입력
- '위로이동'을 눌러서 가장 상단으로 올려주기 (명령어를 찾을 때, Path 환경변수에 등록된 순서대로 찾기 때문에 가장 상단으로 올려주어야 함)
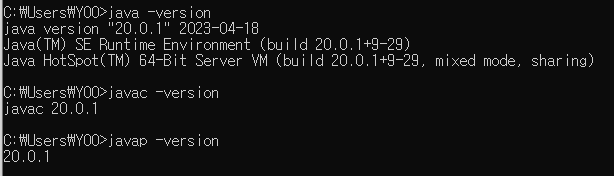
6) 환경변수 확인
1. CMD 창을 켠 이후 java -version 입력
2. javap -version과 javap -version 입력하여 버전 확인
Spark 설치
1. 폴더 만들기
- C Drive 밑에 Spark와 Hadoop라는 폴더를 만들어 준다.
- Spark: C:\Spark
- Hadoop: C:\Hadoop
2. 아래 링크에서 가장 최신버전의 Spark를 다운로드한다.
https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
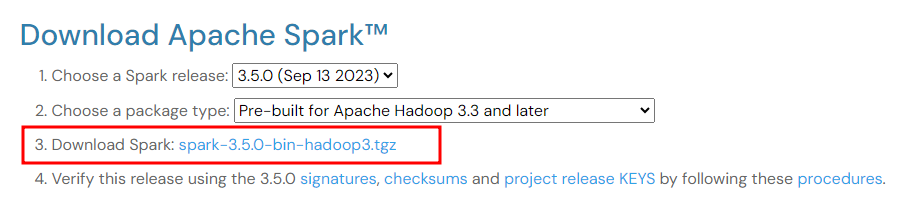
3. tgz 파일 형식은 linux에서 쓰는 압축파일 형식이다. Windows에서는 cmd에서 해당 폴더의 압축을 풀어줄 수 있다.
- cmd를 통해 해당 파일이 있는 위치로 이동한다.
- 압축 해제 명령어
tar -zxvf [압축 해제할 파일 이름.tgz]
ex) tar -zxvf spark-3.5.0-bin-hadoop3.tgz4. 압축이풀린 데이터를 이전에 생성한 "Spark" 폴더로 옮겨준다.
5. winutils.exe와 hadoop.bll 파일을 다운로드한다.
아래 링크에서 winutils.exe와 hadoop.bll 을 다운로드 한다.
https://github.com/cdarlint/winutils/tree/master/hadoop-2.7.7/bin
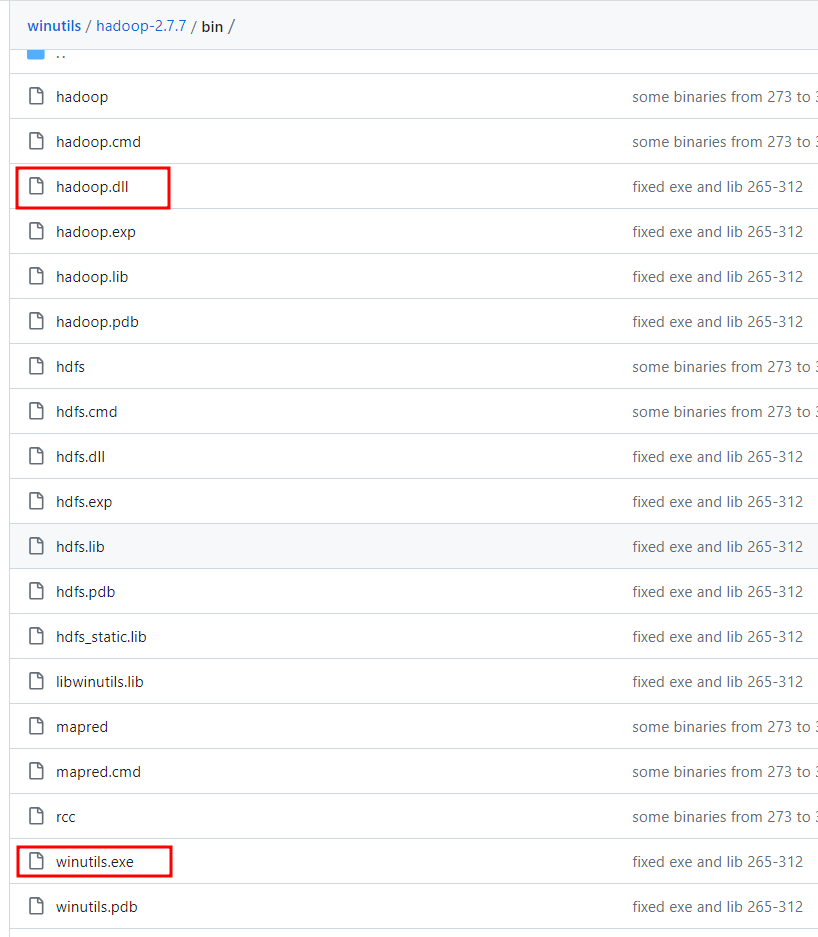
6. Hadoop 폴더에 "bin" 폴더를 만들고, 다운 받은 winutils.exe와 hadoop.bll을 옮겨준다

환경변수 설정
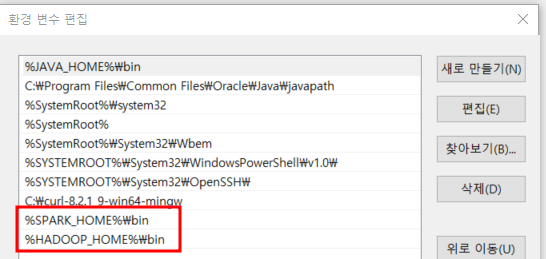
1. SPARK_HOME과 HADOOP_HOME을 설정한다.
- 시스템 환경 변수 편집 > 환경 변수에 들어간다
- 여기서 시스템 변수의 새로 만들기를 누르고 시스템 변수로 아래 환경 변수들을 설정한다.
- HADOOP_HOME: C:\Hadoop
- SPARK_HOME: C:\Spark\spark-3.5.0-bin-hadoop3
- Spark에 폴더에 옮겨놓은 폴더이름으로 세팅해야한다.
2. Path 수정
- Path에 아래 두개 path를 추가한다
- %SPARK_HOME%\bin
- %HADOOP_HOME%\bin