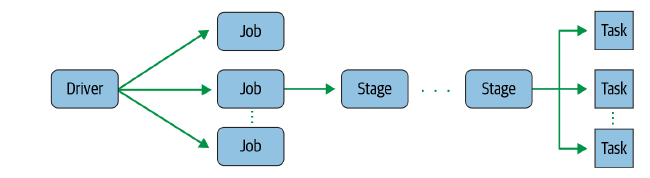
Spark 란버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트대규모 데이터를 처리하기 위한 클러스터 컴퓨팅 프레임워크 Java로 개발되었으며 Python, Sql, Scala등의 언어들을 지원하여, 어떤 언어로 개발하든 성능에 큰 이슈 없도록 설계Hadoop와 달리 MapReduce 로직중 Map를 메모리에서 처리하기에 Hadoop보다 속도가 빠름빅데이터 처리 관련 다양한 기능 제공https://spark.apache.org/releases/spark-release-3-5-0.html Spark Release 3.5.0 | Apache SparkSpark Release 3.5.0 Apache Spark 3.5.0 is the sixth release in the 3.x series. With sig..