Bucketing과 File System Partitioning
- 둘다 Hive 메타스토어의 사용이 필요: saveAsTable
- 데이터 저장을 이후 반복처리에 최적화된 방법으로 하는 것
Bucketing
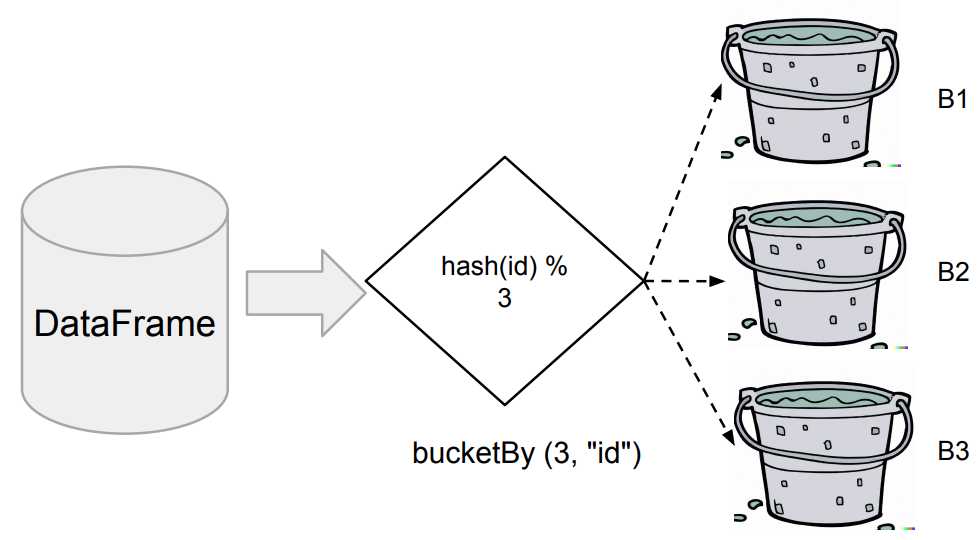
- DataFrame을 특정 ID를 기준으로 나눠서 테이블로 저장
- 먼저 Aggregation 함수나 Window 함수나 JOIN에서 많이 사용되는 컬럼이 있는지 확인
- 있다면 데이터를 이 특정 컬럼(들)을 기준으로 테이블로 저장
- 다음부터는 이를 로딩하여 사용함으로써 반복 처리시 시간 단축
- DataFrameWriter의 bucketBy 함수 사용
- Bucket의 수(첫번째 인자)와 기준 ID 지정(두번째 인자)
- 데이터의 특성을 잘 알고 있는 경우 사용 가능 (그 특성을 이용하여 최적화)
- CF) https://towardsdatascience.com/best-practices-for-bucketing-in-spark-sql-ea9f23f7dd53
코드 예시
df_user_session_channel.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_usc")
File System Partitioning
- 데이터의 특정 컬럼(들)을 기준으로 폴더 구조를 만들어 데이터 저장 최적화
- 위의 컬럼들을 Partition Key라고 부름
- 다수의 컬럼을 지정하는 것도 가능
- 데이터를 Partition Key 기반 폴더 (“Partition") 구조로 물리적으로 나눠 저장
DataFrame에서 이야기하는 Partition이 아님!- Hive에서 사용하는 Partitioning을 말함
- Partitioning의 장점
- 굉장히 큰 로그 파일을 데이터 생성시간 기반으로 데이터 읽기를 많이 할때 유용(loading overhead 시간 단축)
- 데이터 자체를 연도-월-일의 폴더 구조로 저장
- 보통 위의 구조로 이미 저장되는 경우가 많음
- 이를 통해 데이터를 읽기 과정을 최적화 (스캐닝 과정이 줄어들거나 없어짐)
- 데이터 관리도 쉬워짐 (Retention Policy 적용시)
- 데이터를 재정리할 필요도 없음
- external table형태로 스키마를 매핑하여 처리 가능
- Retention Policy : 만약 데이터를 1년만 저장한다면, 자동으로 1년이 지난 데이터는 삭제가능
- 굉장히 큰 로그 파일을 데이터 생성시간 기반으로 데이터 읽기를 많이 할때 유용(loading overhead 시간 단축)
- DataFrameWriter의 partitionBy 사용하여 저장
- Partition key를 잘못 선택하면 엄청나게 많은 파일들이 생성됨
- Cardinality가 낮은 컬럼을 써야함 (가능한 값의 경우의 수가 적은것으로 선택)
- EX) 지역, Date등

Partitioning Code in Pyspark
1. SparkSession 생성
from pyspark.sql import *
from pyspark.sql.functions import *
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Spark FS Partition Demo") \
.master("local[3]") \
.enableHiveSupport() \
.getOrCreate()2.아래 데이터를 읽어온다. (애플 주가 가격 데이터)
df = spark.read.csv("appl_stock.csv", header=True, inferSchema=True)
df.printSchema()
3. 파티션 키가 될 컬럼들을 생성한다 (년, 월)
df = df.withColumn("year", year(df.Date)) \
.withColumn("month", month(df.Date))4. 파티션키(year, month)를 기준으로 데이터를 저장한다.
# spark.sql("DROP TABLE IF EXISTS appl_stock") # 만약 기존 테이블이 있으면 drop
df.write.partitionBy("year", "month").saveAsTable("appl_stock")5. 저장된 데이터를 확인한다.
app_stock 테이블 안의 파티션을 확인한다. (year중심)
!ls -tl spark-warehouse/appl_stock/
특정 year안의 month 파티션을 확인한다.
!ls -tl spark-warehouse/appl_stock/year\=2010/
특정 month안의 데이터를 확인한다.
!ls -tl spark-warehouse/appl_stock/year\=2010/month\=12/
6. 특정 파티션의 조건을 걸어 데이터를 읽어온다.
- 아래는 2016년 12월의 데이터를 읽어오는 코드이다.
#pyspark
df = spark.read.table("appl_stock").where("year = 2016 and month = 12")
df.show(10)#sparksql
spark.sql("
SELECT *
FROM appl_stock
WHERE year = 2016
AND month = 12
").show(10)
위 포스팅은 [파이썬으로 해보는 Spark 프로그래밍 with 프로그래머스] 강의를 듣고 정리한 내용입니다
728x90
반응형
'Spark & Hadoop > Spark' 카테고리의 다른 글
| [Spark] Spark Action의 구성요소(Job, Stages, Tasks)와 Spark의 연산 (Transformations /Actions / Lazy Execution) (0) | 2024.05.05 |
|---|---|
| [Spark] Spark 프로그램 구조 (Driver, Executor), Spark Cluster Manager (0) | 2024.05.05 |
| [Spark] Schema Evolution (1) | 2023.10.03 |
| [Spark] Spark 파일 Type 종류 및 Pyspark로 데이터 Write하는 방법 (Parquet / AVRO) (1) | 2023.10.03 |
| [Spark] Windows 10에 Spark 설치하기 (Java설치, 환경변수 세팅) (1) | 2023.10.02 |