Spark 프로그램 실행 환경
- 개발/테스트/학습 환경 (Interactive Clients)
- 노트북 (주피터, 제플린)
- Spark Shell
- 프로덕션 환경 (Submit Job)
- spark-submit (command-line utility): 가장 많이 사용됨
- 데이터브릭스 노트북:
- 노트북 코드를 주기적으로 실행해주는 것이 가능
- REST API:
- Spark Standalone 모드에서만 가능
- API를 통해 Spark job 실행
- 실행코드는 미리 HDFS등의 파일 시스템에 적재되어 있어야함
Spark 프로그램의 구조
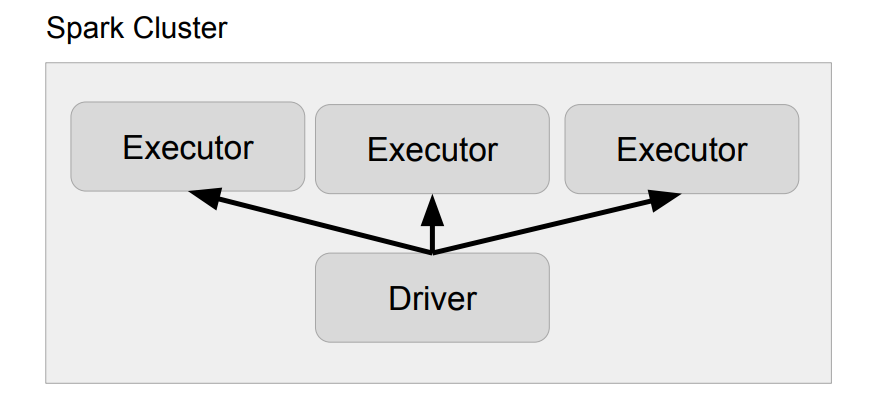
1. Driver
- 실행되는 코드의 마스터 역할 수행 (YARN의 Application Master)
- 컨테이너를 하나 잡아서 돌게됨.
- 사용자 코드를 실행하며 실행 모드(client, cluster)에 따라 실행되는 곳이 달라짐
- client mode : Driver가 Yarn 클러스터 밖에서 돔. 기본적으로 개발, 학습, 디버깅을 하기 위해 개발중인 spark 코드를 spark cluster밖에서 돌림
- cluster mode : 개발이 끝난 코드를 spark cluster안에서 돌림
- 코드를 실행하는데 필요한 리소스를 지정함
- --num-executors : spark job을 종료하기 위해 몇개의 executor 수를 지정
- --executor-cores : executor마다 몇개의 cpu를 쓸것인지
- --executor-memory : executor마다 memory를 얼마나 쓸것인지
- SparkSession을 만들어 Spark 클러스터와 통신 수행
- Cluster Manager (YARN의 경우 Resource Manager)
- Executor (YARN의 경우 Container)
- 사용자 코드를 실제 Spark 태스크로 변환해 Spark 클러스터에서 실행
2. Executor
- 실제 태스크를 실행해주는 역할 수행 (JVM): Transformations, Actions
- YARN에서는 Container가 됨
Spark Cluster Manager
1. Local Mode
- 개발/테스트용 (실습을 하는 환경)
- Spark Shell, IDE, 노트북
- 하나의 JVM이 클러스터로 동작
- Driver와 하나의 Executor 실행

- [n] : 몇개(n)의 cpu를 쓸 것인지 지정
- n은 코어의 수
- Executor의 스레드 수가 됨
- local[*] : 컴퓨터에 있는 모든 코어 사용

2. YARN
- 두 개의 실행 모드가 존재: Client vs. Cluster
- Client Mode
- Driver가 Spark 클러스터 밖에서 동작
- 즉, Spark job을 제출하는 Client위에 Spark Driver가 생성
- YARN 기반 Spark 클러스터를 바탕으로 개발/테스트 등을 할 때 사용
- 또는 Airflow와 결합하여 Airflow에 Spark log을 받아볼 때 사용
- Client가 종료되면 실행중인 Spark Application도 종료
- Driver가 Spark 클러스터 밖에서 동작

- Cluster Mode
- Driver가 Spark 클러스터 안에서 동작
- 즉, Cluster 위 Node가운데 Spark Driver가 생성
- 하나의 Container 슬롯을 차지
- 큰 DataFrame을 보기 위해 Driver에 자원이 많이 필요한 경우 Cluster Mode로 실행
- 실제 프로덕션 운영에 사용되는 모드

- Client Mode VS Cluster Mode

| Cluster Manager | 실행모드 (deployed mode) | 프로그램 실행방식 |
| local[n] | Client | Spark Shell, IDE, Notebook |
| YARN | Client | Spark Shell, Notebook |
| YARN | Cluster | spark-submit |
CF) 기타 Cluster Manager
- Kubernetes : 대용량 컨테이너 클러스터가 이미 있는 경우
- Mesos : 대용량 컨테이너 클러스터가 이미 있는 경우
- Standalone : spark 자체에서 제공하는 옵션을 쓰고자 하는 경우, 많이 쓰지 않음
참고자료
- [파이썬으로 해보는 Spark 프로그래밍 with 프로그래머스] 강의
- https://livebook.manning.com/book/spark-in-action/chapter-10/183
728x90
반응형
'Spark & Hadoop > Spark' 카테고리의 다른 글
| [Spark] Spark 소개 및 Spark관련 정보 모음 (Spark 구성요소, 작동방식 등) (1) | 2024.05.05 |
|---|---|
| [Spark] Spark Action의 구성요소(Job, Stages, Tasks)와 Spark의 연산 (Transformations /Actions / Lazy Execution) (0) | 2024.05.05 |
| [Spark] HDFS Bucketing & Partitioning (Partitioning pyspark 코드 예시) (0) | 2023.10.08 |
| [Spark] Schema Evolution (1) | 2023.10.03 |
| [Spark] Spark 파일 Type 종류 및 Pyspark로 데이터 Write하는 방법 (Parquet / AVRO) (1) | 2023.10.03 |