PostgreSQL이란
- 오픈소스로 개발된 관계형 데이터베이스 ( ORDBMS)
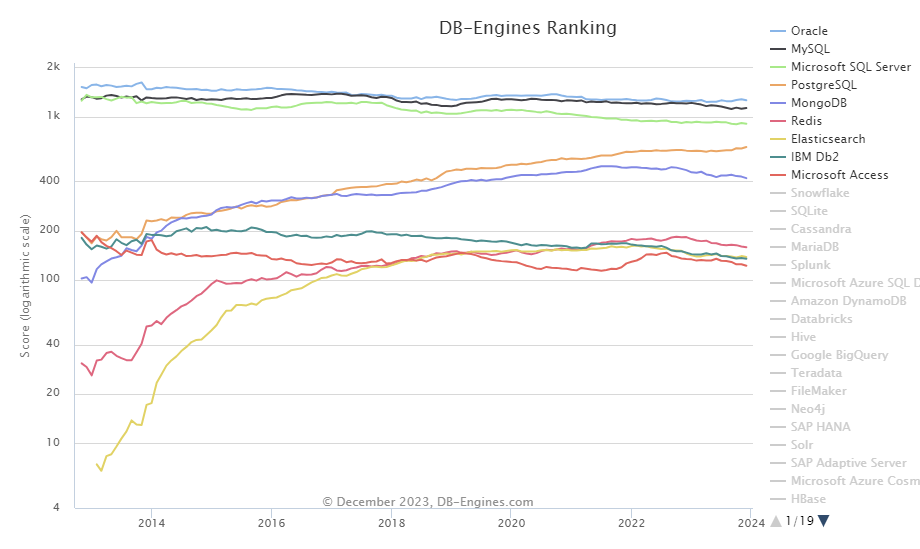
- 다양한 영역에서 활용되고 있으며, 오라클/MySQL/MsSQL다음으로 많이 사용되는 RDBMS
PostgreSQL 특징
1. 라이센스 비용이 전혀 들지 않음
- PostgreSQL은 BSD(Berkeley Software Distribution) 라이센스를 활용하여 개발되었음
- PostgreSQL은 자유로운 오픈 소스 라이선스를 통해 원하는 대로 DBMS를 사용, 수정 및 배포할 수 있음
- 따라서 데이터 volume가 커지더라도 라이센스 문제가 없기에, 기업에서는 부담이 전혀 없음
- CF) BSD(Berkeley Software Distribution)
- BSD는 미국 캘리포니아 대학교 버클리의 CSRG(Computer System Research Group)에서 1977년 부터 1995년까지 개발한 유닉스 프로그램 운영체제
- PostgreSQL은 오픈 소스 프로젝트이기에, 모든 사람이 사용 및 소유할 수 있음
2. 최다 SQL 기능 지원

3. 최다 ANSI SQL 표준 지원
- 전체 179항목 중 170항목인 약 95%의 SQL표준 지원
4. 객체 관계형 데이터베이스 관리 시스템(ORDBMS):
- 관계형과 객체 지향 기능을 결합한 하이브리드 데이터베이스 시스템
- C++처럼 객체 지향 프로그래밍과 관계형/프로시저 프로그래밍 사이의 가교 역할
- 이를 통해 객체와 테이블 상속을 정의하여 더 복잡한 데이터 구조로 변환할 수 있음
- ORDBMS는 엄격한 관계형 모델과 맞지 않는 데이터를 처리할 때 유용하기에, 구조화된 데이터 유형과 복잡한 데이터 유형을 모두 관리하는 데 가장 적합
5. 사용자 정의 가능
- 사용자 정의 함수 및 저장 프로시저를 지원하며 다른 데이터베이스 시스템보다 더 많은 기능을 포함함
- 플러그인을 개발하여 요구사항에 맞게 PostgreSQL을 사용자 정의할 수 있음
- 사실 이미 다양한 플러그인이 개발되어 다양하게 사용 가능함.
- 또한 PostgreSQL을 사용하면 C/C++, Java 등과 같은 다른 프로그래밍 언어로 만든 사용자 정의 함수를 통합할 수 있음
6. 다양한 OS에서 사용 가능
- PostgreSQL은 Linux, Unix, Mac OS X 및 Microsoft Windows를 포함한 거의 모든 운영 체제에서 실행되며 Raspberry Pi 보드와 같은 상용 하드웨어에서도 실행가능함.
7. ACID 준수
- 최고수준의 ACID를 준수하고 있으며, 이를 통해 높은 동시 트랜잭션을 달성하고 NoSQL 지원 가능
CF) MySQL은 버전 8.0부터 NoSQL 지원을 제공
ACID란
- 원자성(Atomicity) : 트랜잭션의 작업 내용이 데이터베이스에 모두 반영되거나, 아예 반영되지 않음. 즉, 작업 단위를 일부분만 실행하지 않는다는 것을 의미
- 일관성(Consistency) : 트랜잭션이 성공적으로 완료되면 일관적인 DB상태를 유지해야함. (Datatype이 변하지 않는 등, 상태 변화가 일어나지 않는것을 의미)
- 독립성(Isolation) : 하나의 트랜잭션 작업이 수행 시 다른 트랜잭션 작업이 중간에 수행되지 않음. 즉, 트랜잭션 작업 사이의 간섭이 없으며, 서로 간섭할 수도 없음.
- 영구성(Durability) : 트랜잭션이 성공적으로 완료되면 수행된 트랜잭션은 영원히 반영됨. commit을 통하여 트랜잭션 작업 내용을 완료할 수 있음
5. MVCC (Multi-Version Concurrency Control) (다중버전 동시성 제어)
https://www.postgresql.org/docs/7.1/mvcc.html
- PostgreSQL은 동시 트랜잭션을 허용하는 다중 버전 동시성 제어(MVCC) 기능을 구현한 최초의 DBMS
- 동시성 제어 : 다수의 사용자가 동시에 DBMS 트랜잭선을 일으켜 상호간섭이 발생하는 상황에서, 데이터베이스를 보호하는 통제방법. 동시성을 허용하면 DBMS에 큰 손상을 입힐 수 있기에 이를 통제하는 것이 중요
- 다중버전 동시성 제어(MVCC) : 동시성 제어의 방법 중 하나로, 데이터에 접근하는 모든 사용자는 갱신/변경된 데이터를 이전 데이터와 버전을 다르게 하여 관리하고, 이를 기반으로 일관성을 유지하는 방법
- 이를 통해 여러 사용자가 동일한 레코드를 한 번에 변경할 수 있음
- 단점은 사용하지 않는 데이터가 계속 쌓이기에, 주기적으로 데이터를 정리해주어야 함
- 물론 PostgreSQL은 Autovaccume 기능을 제공하지만, 그래도 사람이 주기적으로 관리해주어야함.
6. 대규모의 활발한 지원 커뮤니티
- PostgreSQL에는 헌신적인 개발자 및 자원 봉사자 커뮤니티가 있음
- 이 커뮤니티는 PostgreSQL 글로벌 개발 그룹을 통해 PostgreSQL을 지속적으로 유지 관리하고 업데이트함
7. 지리 정보 시스템(GIS) 및 공간 참조 시스템(SRS)
- https://ysyblog.tistory.com/107
- GIS : 공간 및 지리적 데이터를 캡처, 저장, 분석
- SRS : 좌표 기반 시스템을 정의하여 공간에서 위치를 찾음
- PostgreSQL은 PostGIS 확장을 통해 이 기능을 제공
- CF) MySQL은 이 기능을 내장형으로 제공
8. 다양한 데이터 유형 제공
- 숫자, 문자, 날짜 및 시간, 공간, JSON 데이터, 기하학, 열거형, 네트워크 주소, 배열, 범위, XML, hstore 등등..
- 또한 PostgreSQL은 JSON과 JSONB 포멧을 모두 사용 가능
https://www.postgresql.org/docs/9.5/functions-json.html
| JSON | JSONB | |
| 데이터 저장방식 | 그대로 값을 저장 | 바이너리 형태로 저장 |
| Write Cost | 적음 (그대로 저장하기에) | 많음 |
| Read Cost | 많음 | 적음 |
| 인덱싱 | 불가능 | 가능 |
| 유효성 체크 | O | O |
| 사용처 | 로그 데이터 | 사용자 추적 데이터 (시간에 따라 계속 업데이트 해주어야 하는 경우) |
9. 초대형 데이터베이스 관리가능
https://www.postgresql.org/docs/current/limits.html
10.복잡한 쿼리 작성에 유리함
10-1 다양한 JOIN방식 지원
- Nested Loop 조인
- Sort Merge 조인
- 해시 조인 (Hybrid 해시 조인 지원)
10-2 Parallel Processing(병렬처리)
- PostgreSQL 9.6 부터 병렬 처리를 지원한다.
- 병렬 처리는 Parallel Scan, Parallel Group by, Parallel Join을 지원
10-3 Parallel Index Scan
- PostgreSQL 10부터는 Parallel Index Scan 기능 제공
- Parallel Index Scan 기능은 Index Full Scan 뿐만 아니라 Index Range Scan 시에도 동작
- 처리 순서
- 1) 조건절 범위에 해당하는 "Start 리프 블록"과 "End 리프 블록"의 위치를 계산
- 2) 처리 범위가 인덱스 병렬 처리를 할 정도로 큰지 확인
- 3) 만일 크다면, 크기에 따라서 Worker 개수를 설정한 후에, "Start" ~ "End" 범위를 나눠서 처리
- 4) 만일 작다면, 싱글 프로세스로 처리
10-4 Query Optimizer
PostgreSQL에는 쿼리를 분석하고 가장 효율적인 실행 계획을 결정할 수 있는 강력한 Query Optimizer Tool 이 있습니다.
Optimizer Tool 은 테이블의 데이터 분포, 인덱스의 존재 및 여러 작업의 비용과 같은 다양한 요소를 고려하여 쿼리를 실행하는 가장 좋은 방법 결정
10-5 Indexing
PostgreSQL은 B-tree, Hash, GiST, GIN, SP-GiST 를 포함한 광범위한 인덱스 유형을 지원하므로 효율적인 데이터 검색 가능
Query Optimizer Tool 는 이러한 인덱스를 사용하여 쿼리를 실행하는 데 필요한 데이터를 신속하게 찾을 수 있으므로 데이터 검색에 필요한 시간을 줄일 수 있음
10-6 MVCC
10-7 Cost-Based Optimization
Postgresql 은 Cost-Based Optimization model 을 사용하는데, 이 model 은 서로 다른 작업을 실행하는 데 드는 비용을 추정하고 추정 비용이 가장 낮은 계획을 선택
따라서 데이터 크기, 인덱스 존재 및 테이블의 데이터 분포와 같은 요인을 고려하여 쿼리 실행 방법에 대한 정보에 입각하여 결정
10-8 사용자 정의 기능
PostgreSQL은 User-Defined Functions 을 지원하며, User-Defined Functions 와 쿼리에서 사용할 수 있는 Function 를 만드는 데 사용할 수 있습니다.
이를 통해 사용자는 데이터베이스의 기능을 확장하고 특정 사용 사례에 최적화된 Custom Function 을 만들 수 있습니다.
10-9
고급 쿼리 및 데이터 처리 기능
PostgreSQL은 Window functions, Common Table Expressions (CTEs), 풍부한 집계 함수 등과 같은 고급 쿼리 기능을 제공하
11. Partial Index
- 전체 데이터의 부분집합에 대해서만 인덱스를 생성하는 기능
- 특정 범위에 대해서만 인덱싱을 할 수 있기 때문에 특히 대량 데이터의 일부 값에 대해 인덱스를 생성할 경우, 인덱스 크기도 작고 관리하는 리소스도 줄일 수 있는 이점이 있음
- 즉, 필요한 부분만 인덱스를 생성하기 때문에 저장공간에 대한 이점이 아주 크고 나아가 데이터 삭제, 추가, 갱신에 따른 인덱스 유지관리 비용도 절약할 수 있음
12. Secondary Index 생성가능
- 보조 인덱스(Secondary Index)라고도 불리며, 물리적으로 테이블을 정렬하지 않음
- 정렬된 별도의 인덱스 페이지를 생성하고 관리
- Primary Key 이외에 필요한 정렬 기준이 있을 경우 사용
- 테이블 당 여러 개를 가질 수 있다.
- Secondary Index 는 인덱스 페이지와 데이터 페이지가 구분되어 있다.
- Secondary Index의 단점
- 일반 index(Cluster Index)보다 검색 속도가 느림
- Data Record 가 Index 순서대로 정렬되어 있지 않아 범위 조건으로 검색 시에 많은 I/O가 발생할 수 있음.(성능 저하)
- 남용하면 시스템의 성능 저하가 발생할 수 있음
13. Materialized View 지원
- 일반 view와는 다르게 snapshot이라고 불림.
- view 생성 시 설정한 조건의 쿼리 결과를 별도의 공간에 저장하고 쿼리가 실행될 때 미리 저장된 결과를 보여주어 성능 향상
- 실시간 노출 필요성이 적은 통계성 쿼리나, 자주 update 되지 않는 테이블에 생성할 때 효과적임
| 일반 VIEW | MATERIALIZED VIEW | |
| 동작 방식 | 실행시 정의된 쿼리를 실행하여 결과를 리턴 | 정의된 쿼리를 미리 실행하여 물리적으로 데이터를 가지고 있으며 그 데이터 내에서 결과를 리턴 |
| 데이터 싱크 | 실행시 원시 데이터를 조회 | REFRESH MATERIALIZED VIEW 를 통해 싱크 |
| 장점 | 데이터 싱크 불 필요 | 이미 데이터가 생성되어 있기 때문에 조회속도가 빠르다 |
| 단점 | 정의된 쿼리 속도가 느리면 view도 느리다. | 데이터 싱크를 주기적으로 맞춰야 한다. |
14. 상속기능
- 부모테이블을 생성 후 상속기능을 이용해 하위 테이블을 만들 수 있음
- 하위 테이블은 상속받은 부모테이블의 컬럼을 제외한 컬럼만 추가로 생성하면 됨
- 상위 테이블에서 조회 시 기본적으로 하위 테이블의 데이터까지 모두 조회 가능
- 데이터 변경 시에도 하위 테이블까지 모두 반영
단점
1. CRUD (Create, Read, Update, Delete)
- PostgreSQL는 복잡한 쿼리와 대규모 서비스에 특화된 대신, 단순 CRUD 성능은 Mysql보다 떨어짐
- 특히 UPDATE가 가장 취약함
- PostgreSQL UPDATE시 내부적으로는 새 행이 INSERT되고 이전 데이터는 삭제 표시됨
- 모든 인덱스에는 행의 실제 위치값에 대한 링크가 표기되어 있는데, 행이 업데이트되면 변경된 위치값에 대한 인덱스 정보도 업데이트가 필요
- 즉 postgresql의 update는 값이 바뀌는 것이 아닌, 값을 delete한 후 insert하는 방식임
출처
https://postgresql.kr/blog/pg_phantom_read.html
https://www.postgresql.org/about/press/presskit14/ko/
https://aws.amazon.com/ko/compare/the-difference-between-mysql-vs-postgresql/
https://techblog.woowahan.com/6550/
https://www.integrate.io/ko/blog/postgresql-vs-mysql-which-one-is-better-for-your-use-case-ko/
https://storycode.tistory.com/449
https://d2.naver.com/helloworld/227936
https://link.coupang.com/a/d0Nx5u
쿠잉 손잡이 있음 무타공 디지털 도어락 - 도어락 | 쿠팡
현재 별점 4.8점, 리뷰 478개를 가진 쿠잉 손잡이 있음 무타공 디지털 도어락! 지금 쿠팡에서 더 저렴하고 다양한 도어락 제품들을 확인해보세요.
www.coupang.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
'SQL & DB > PostgreSQL' 카테고리의 다른 글
| [PostgreSQL] Json(Jsonb) 컬럼 Query 방법 (->, ->>과 json_array_elements) (1) | 2024.07.07 |
|---|---|
| [PostgreSQL] generate_series을 활용한 날짜/시간 더미 데이터 생성 (월단위, 일단위, 시간단위) (1) | 2024.06.30 |
| [PostgreSQL/MYSQL] 날짜/시간 계산(INTERVAL타입, age함수) (DATEDIFF, TIMESTAMPDIFF) (0) | 2023.11.24 |
| [PostgreSQL] CSV File를 Table에 삽입(Import)하기. (2) | 2023.03.05 |
| [PostgreSQL] 값 비교 - 조건을 0과 1로 표현하기 (0) | 2023.03.05 |