YARN
- 세부 리소스 관리가 가능한 범용 컴퓨팅 프레임웍
- 각 Application (MapReduce, HBase 등) 실행에 필요한 Resource(Cpu, Memory, Disk)를 할당하고 모니터링
- MapReduce의 단점을 극복하기 위해 하둡 2.0부터 제공
- CF) MapReduce란 : https://ysyblog.tistory.com/347
[Hadoop] 맵리듀스(MapReduce) Programming
맵리듀스 프로그래밍 특징 큰 데이터를 처리할 수 있는데에 목표 데이터 셋의 포맷도 하나로 단순화하였고, 변경 불가 데이터 셋의 포멧은 Key, Value의 집합이며 변경 불가(immutable) 데이터 조작은
ysyblog.tistory.com
YARN의 구성요소
- Cluster
- Job 수행을 위해 여러 대의 컴퓨터가 네트워크로 연결된 것
- Cluster를 구성하는 개별 컴퓨터를 node라고 함
- Container
- Node Manager 들이 가지고 있는 Resource (CPU, Disk, Memory) (Java의 JBM과 비슷)
- 모든 job은 여러개의 task로 분리되고, 각 task는 하나의 Container에서 실행
- 즉, 다수의 컨테이너가 한 Node Manager 밑에 있을 수 있음
- Application Master가 필요한 Resource만큼 요청하며, Resource Manager가 승인
- Resource Manager(Master Node)
- Cluster에 1개만 존재하며, Cluster의 Resource를 관리하고 Scheduler와 Application Manager를 조정하는 역할 수행
- Client로 부터 작업 요청을 받으면, 작업을 진행할 Application Master를 실행
- Cluster 내의 Node Manager들과 통신을 해서 할당된 자원과 사용중인 자원의 상황을 모니터링
- Node Manager(Slave Node)
- Resource Manager의 요구에 따라 자신의 Resource을 넘겨주는 역할을 함
- 노드 당 한개씩 존재하며, Container의 Resource 현황을 모니터링하고, 관련 정보를 Resource Manager에게 알리는 역할을 한다.
- 두 종류의 프로세스를 지원
- Application Master
- Task
- Scheduler (스케줄러)
- Node Manager들의 자원 상태를 관리하며 부족한 리소스를 할당
- 자원 상태에 따라서 task들의 실행 여부를 허가해주는 역할인 스케쥴링 작업만 담당
- Node Manager들의 자원 상태를 Resource Manager에게 통지한다.
- Application Manager
- Node Manager에서 작업을 위해 Application Manager를 실행하고, Application의 실행 상태를 관리하여 그 상태를 Resource Manager에게 통지
- Application Master
- Scheduler로부터 적절한 Container를 할당 받고, 프로그램의 실행 상태를 모니터링 및 관리
- YARN에서 실행되는 하나의 태스크를 관리하는 마스터 서버를 의미하며 Application당 1개가 존재
YARN의 작동방식

- Client가 Spark Code와 환경 정보를 Resource Manager에게 넘김
- 실행에 필요한 파일들은 application ID에 해당하는 HDFS 폴더에 미리 복사됨
- Resource Manager이 Scheduler에게 job을 실행해도 되는지 허가를 받으며 Node Manager으로부터 Container를 받아 Application Master 실행
- Application Master : YARN Cluster가 시킨 Task의 주인 역할을 함.
- YARN Application마다 하나의 Application Master가 생김 (프로그램 마다 하나씩 할당되는 프로그램 마스터에 해당)
- Spark Cluster 모드일 경우 Driver Node 선정
- Application Master이 Resource Manager 으로 코드에 실행에 필요한 Resource(Container)를 받아옴
- Resource Manager은 data locality를 고려해서 Resource(Container)를 할당
- Resource Manager는 Application Master에게 쓸 수 있는 다른 노드들에 대한 자원과 접속 정보를 공유
- Application Master은 할당받은 리소스를 Node Manager 을 통해 Container 론치하고 그 안에서 코드를 실행 (Task)
- 이 때 실행에 필요한 파일들이 HDFS에서 Container가 있는 서버로 먼저 복사
- Task들은 자신의 상황을 주기적으로 Application Master 에게 업데이트 (heartbeat)
- Task 가 실패하거나 보고가 오랜 시간 없으면 Task 를 다른 컨테이너로 재실행
- 데이터는 HDFS에 있다고 가정
- 클라이언트 : MapReduce일 수도 있고 Spark일 수도 있음
CF) YARN 설정에 따라 Node Manager가 쓸 수 있는 자원과 Container 각각 에서 사용할 수 있는 자원이 정해짐
- Spark Executor는 Container안에 여러개 생성
- YARN이 할당 가능한 Container수보다 Executor자원을 더 많이 요구하는 경우 Executor가 생성되지 않음

YARN의 스케쥴링 방식
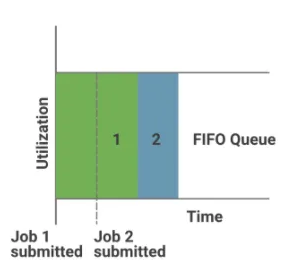
1. FIFO Scheduler (FIRST IN FIRST OUT)
- 가장 기본적인 방식으로 먼저 제출된 job이 처리된 후 다음 job을 실행
- 다른 애플리케이션을 처리하기 위해 이전에 처리하던것이 완료될때 까지 기다려야하기에 공유 클러스터 환경에서 사용하기 부적절함
2. Capacity Scheduler
- 여러개의 Queue를 사용하여 각각의 Queue가 FIFO방식으로 동작
- 아래 그림에서 실행 시간이 긴 job 은 Queue A 에, 실행 시간이 짧은 job 은 Queue B에서 실행
- 동시에 여러개의 job을 처리할 수 있지만, 실행시간이 긴 job은은 FIFO보다 늦게 끝나며, 분리된 Queue가 Resource를 미리 예약해놓기에 전체 클러스터의 효율성이 감소함.

3. Fair Scheduler
- 실행중인 모든 job의 자원을 동적으로 분배하는 방식
- 따라서 미리 자원을 예약할 필요가 없음
- 아래 그림에서 1번 job이 먼저 실행되면 다른 job이 없기에 모든 자원을 활용하지만, 다른 job이 추가로 시작되면 Fair Scheduler는 자원을 다른 job에게 할당해줌.
- 따라서 Cluster의 효율성이 높아지며 작은 job도 빠르게 처리할 수 있음
- 다만 작은 job에게 자원을 주기 위해 큰 job에서 사용하는 자원을 나누는데 어느정도 시간이 소요
- Spark History Server를 보았을때 Executor가 삭제된다면 Fair Scheduler를 사용하고 있는것.

출처
- https://aws.amazon.com/ko/blogs/big-data/tag/apache-hadoop-yarn/
- https://www.researchgate.net/figure/JobTracker-and-TaskTracker_fig4_277935711
- https://karthiksharma1227.medium.com/deep-dive-into-yarn-scheduler-options-cf3f29e1d20d
- https://www.linode.com/docs/guides/how-to-install-and-set-up-hadoop-cluster/
728x90
반응형
'Spark & Hadoop > Hadoop' 카테고리의 다른 글
| [Hadoop] 맵리듀스 프로그래밍 실행 (WordCount) (0) | 2023.08.20 |
|---|---|
| [Hadoop] 하둡(Hadoop) 설치 (on Ubuntu) (0) | 2023.08.14 |
| [Hadoop] Windows에서 우분투 설치 (Ubuntu on WSL2) (Ubuntu 설치시 Error 해결) (0) | 2023.08.10 |
| [Hadoop] 맵리듀스(MapReduce) Programming (0) | 2023.08.09 |
| [Hadoop] 대용량 분산시스템 Hadoop과 MapReduce (Hadoop 1.0, Hadoop 2.0, Hadoop 3.0) (0) | 2023.08.09 |