A/B Test 설계 시 실험군 간의 누출 및 간섭
이번 포스팅에서는 A/B Test 설계를 할 때 실험군 간 간섭이 되는 경우와 이를 해결하는 방법을 알아봅니다.
A/B Test 분석의 가정 : SUTVA

- SUTVA : Stable Unit Treatment Value Assumption
- A/B Test의 내적타당성을 지키기 위한 가정 중 하나 (생존 편향, SRM 등 3장 참고)
- 각 그룹의 unit의 행동은 다른 그룹의 unit에 영향을 받지 않음 (독립)
- 만약 안방의 스위치를 눌렀는데 불이켜지고, 다른 방에 영향을 주지 않는다면 이는 독립이라고 할 수 있음
- 하지만 안방의 스위치를 눌렀는데, 다른 방에 불이 켜치거나, 두꺼비집이 내려가 불이 안켜진다면 독립이라고 할 수 없음
SUTVA 가정을 위반한 경우 : 간섭(Interference)
- 간섭(Interference)으로 정의
- Variants간의 spillover(유출), leakage(누출), 파급효과로도 불림
- 직접 간섭과 간접 간섭이 있음
- 둘다 실험군과 대조군을 연결하고 상호작용하는 중간 매개체가 있는것
- 간섭이 있으면 실제 treatment 효과를 과대/과소평가할 수 있음
- 인과 추론의 noise와 유사
- 간섭으로 인한 편향이 treatment 효과의 상당부분 측정되어, 이를 감소하기 위한 연구가 다수 있음
CF) https://arxiv.org/pdf/2004.12489
Direct Connections (직접 간섭)
- 친구이거나 동시에 물리적인 공간을 방문한 경우 두 unit를 연결되어 간섭을 유발할 수 있음
- EX1 ) 소셜 네트워크 상에서 친구인 경우
- 링크드인/페이스북 같은 SNS에서의 행동은 해당 사이트 내 이웃의 행동에 영향을 받을 수 있음
- 예를 들어 친구가 메시지 보내면 나도 보낼 가능성이 높음.
- 네트워크 효과라고도 불림
- EX 2) 스카이프 통화
- 실험군의 통화 품질을 높인 경우 실험군의 통화량 증가 -> 대조군으로 통화량이 증가
Indirect Connections (간접 간섭)
- 특정 잠재 변수 또는 공유 리소스로 인해 두 unit가 간접적으로 연결 될 수 있음
- Airbnb
- 실험군 구매 증가 → 대조군이 구매할 재고 부족, 매출 하락
- 잠재 변수 또는 공유 리소스 : 한정된 숙소
- Uber/Lyft
- 실험군 이용 증가 → 대조군 사용 드라이버 부족
- 잠재 변수 또는 공유 리소스 : 한정된 드라이버

간접간섭의 예시. 하나의 차량을 두고 두개의 unit이 경합을 한다. 츌처 : https://eng.lyft.com/experimentation-in-a-ridesharing-marketplace-b39db027a66e
- eBay
- 실험군 입찰 장려 → 대조군 낙찰 가능성 하락
- 잠재 변수 또는 공유 리소스: 낙찰은 하나만 가능하다는 점
- 광고 캠페인
- 실험군 광고클릭 증가 → 예산 소진 → 대조군 적은 예산
- 잠재 변수 또는 공유 리소스 : 한정된 광고 예산
- 관련성 모델 훈련
- 실험군의 특정 상품 클릭 증가 → 검색 모델이 특정 상품 상단 노출 → 대조군도 그 상품 클릭
- 실험이 길어질수록 모델 학습을 더 많이 해서 대조군에 대한 영향이 증가
- 잠재 변수 또는 공유 리소스 : 검색 모델
- CPU
- 실험군의 액션 증가 → 웹사이트 서버에 대한 리퀘스트 증가 → 전체적으로 웹사이트가 느려짐 → 부정적인 실험효과 증가
- 잠재 변수 또는 공유 리소스 : 서버 처리 역량
- 사용자보다 더 세분화된 실험 단위
- 실험단위가 페이지 방문 or 세션 단위로 세분화
- "가"라는 사람이 A Session은 실험군 B Session은 대조군으로 할당되는 경우
- 잠재 변수 또는 공유 리소스 : 동일한 유저
- 실험단위가 페이지 방문 or 세션 단위로 세분화
간섭(Interfere)를 해결하는 Practical Solutions
- 간섭을 고려하는 경우
- 실험에 중대한 영향을 받는 경우에만 고려
- 1차적인 행동뿐만 아니라 행동에 대한 잠재적인 반응을 고려
Practical Solutions - Rule-of-Thumb (경험법칙)
도구 변수(Instrumental Variable)
- 중간 매개체 통제
- EX) 메시지를 보내 pageview 을 증가시키는 Test를 하는 경우
- Peer notification(생일/승진)때 메시지가 증가하는데 이를 모델링에 포함
도구변수를 활용하여 Peer notification을 통제한다.
- Peer notification(생일/승진)때 메시지가 증가하는데 이를 모델링에 포함
- Two-Stage Least Squares Instrumental Variable Regression (2sls)
-
도구변수를 사용하는 방법
-
First Stage : 도구변수를 사용하여 문제가 되는 변수를 추정
-
Second Stage : 문제되는 변수를 첫번째 단계에서 추정한 값으로 대체하고 원래 식을 추정

2sls의 원리 출처 : https://youtu.be/m2vNDJ0Cdc4?si=IRDy6Op1wGVghWVO
-
- 주의 사항
- 모든 경우에 작동하지 않을 수 있음
- 특정 실험에 기인한 추가 메시지는 기존보다 큰 효과를 발생시킬 수 있기 때문
Practical Solutions - Isolation
- 매개체를 식별하고 변형군을 격리하여 잠재적인 간섭 제거
- 실험군과 대조군 unit가 잘 나눠지도록 설계
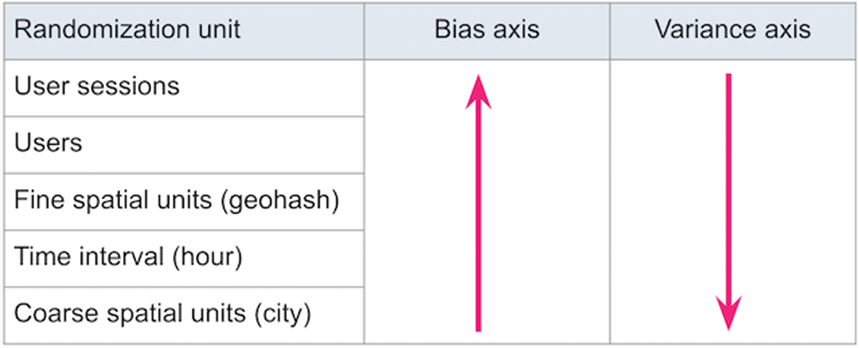
- 대체로 유저 단위의 A/B Test가 아닌 단위를 더 크게 하여 격리
- 다만 단위가 커질수록 편차는 줄지만 분산은 커진다.
- 공유 리소스 분할
- 실험군과 대조군에 각각 리소스 분할
- EX) 광고 캠페인 A/B Test

공유리소스 분할 예시. 실험군과 대조군에 각각 예산을 할당한다. 출처 : https://help.moloco.com/hc/ko-kr/articles/4404658994071-%EC%86%8C%EC%9E%AC-A-B-%ED%85%8C%EC%8A%A4%ED%8A%B8-%EC%84%A4%EC%A0%95%ED%95%98%EA%B8%B0
- 지리기반 랜덤화
- 지역을 랜덤화해서 각 그룹에 설정
- 문제는 지리에 따라 표본 크기가 달라지기에 A/B Test에 대한 분산이 커지고 검정력이 낮아짐

지리기반 랜덤화 예시. 지역을 나누어 대조군과 실험군에 할당하여 간섭을 배제한다. 출처 : https://eng.lyft.com/experimentation-in-a-ridesharing-marketplace-f75a9c4fcf01
- 시간 기반 랜덤화
- 시간을 사용하여 격리
- 실험군, 대조군을 나누지 않고 실험을 하는 것을 의미 (like.. causal effect)
- 시간이 지남에 따라 동일한 사용자에 의해 발생하는 간섭이 중대하지 않아야 함
-
단절적 시계열과 유사 (ITS)
-
특정 event가 발생했을 때 모집단에 시간에 따라 어떤 변화가 있는지 측정
-
시간 흐름에 따른 추정치를 제공할 수 있는 반사실적 모델(예측모델)을 만들고, event 이후의 변화와 비교
-
EX) 코로나 발생 기간때 마스크 의무화 이후 감기 걸리는 사람이 얼마나 감소했는지
-
CF) 준실험 : 연구자가 개입을 하지 않고 이미 존재하는 조건을 이용해 인과관계 추론

단절적 시계열 (ITS)의 원리
-
- 네트워크 클러스터 랜덤화
- 서로 가까운 노드를 클러스터로 구성하여 이를 랜덤화 단위로 사용
- 머신러닝의 Clustering과 유사하지만 차이점은 가까이 있는 사람들끼리 묶는다는것.
- 소셜네트워크 A/B Test 사례
- 제한사항
- 완벽하게 격리된 클러스터로 자르는 것은 불가능
- 클러스터 수가 많을수록 분산이 작아지지만 격리가 잘 되지 않을 수 있으며 더 큰 편향을 가져옴

네트워크 클러스터 랜덤화 예시. 클러스터 단위로 실험군과 대조군을 할당하여 간섭을 최대한 배제한다. 출처 : https://www.linkedin.com/blog/engineering/ab-testing-experimentation/detecting-interference-an-a-b-test-of-a-b-tests
- 서로 가까운 노드를 클러스터로 구성하여 이를 랜덤화 단위로 사용
- 네트워크 에고(ego) 중심 랜덤화
- 네트워크 클러스터 랜덤화에서 발전된 개념
- 에고(ego, Focused individual) 올터(alter, The individuals it is immediately connected to) 로 클러스터 구성
- EX) ego : 스터디 장, alter : 스터디 원들
- 작동 원리
- ego를 기준으로 ego와 alter들을 클러스터 분리
- 분리 후 alter들에게 실험을 집행
- 실험효과는 ego들을 비교하여 분석.
- 더 나은 격리와 더 작은 분산을 얻을 수 있음
- 클러스터 단위로 하면 단위가 커지기에 분산도 커지지만, ego중심 랜덤화는 결국 user(ego)끼리 비교하는 것이기에 분산이 작아지게 됨.
- ego와 alter에 대한 변형군 할당을 별도로 결정할 수 있음

네트워크 에고 중심 랜덤화 예시. 에고들끼리 비교하여 실험의 효과를 측정한다. 출처 : https:// arxiv.org/pdf/1903.08755
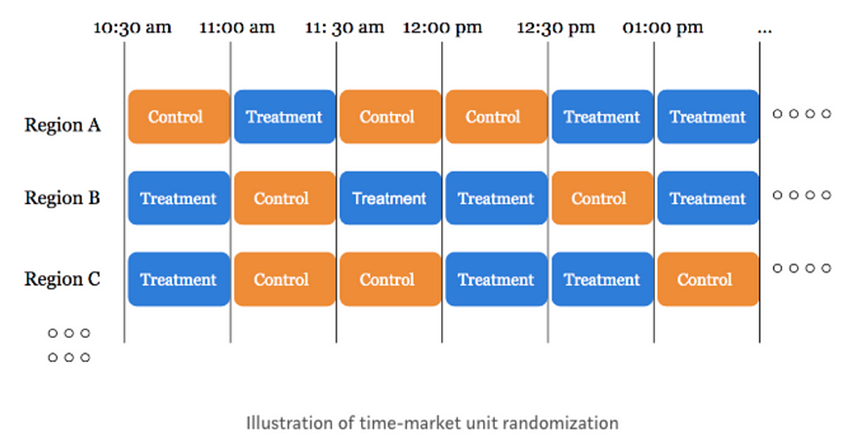
- Switchback Design
- SNS 뿐만 아니라 일상 생활에서도 지리적 위치가 가까운 경우 네트워크 효과가 있음 (ex. 입소문)
- 네트워크 간섭을 완화하기 위해 별도의 region 및 time 단위에서 treatment를 random화
- 유저 기준의 A/B Test에 비해 편향이 적어짐 (물론 분산은 커짐)
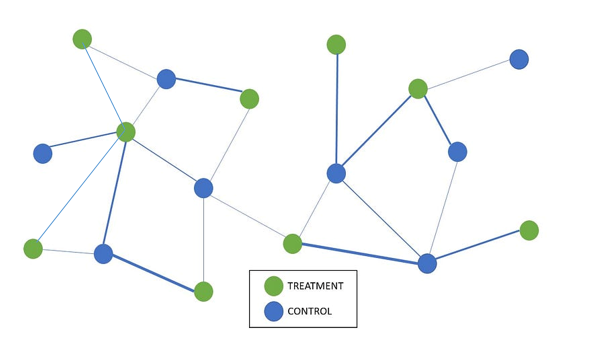
Edge-Level Analysis
- 네트워크 A/B Test에서 상호작용(엣지)는 위 4개 case로 구분 가능하며 4개 case의 경계 사이의 차이를 사용하여 편향되지 않은 델타 추정
- Treatment -> Treatment, Treatment -> Control, Control -> Treatment, Control -> Treatment
- EX) Treatment -> Control과 Control -> Control Case를 비교
- 실험군 친화성 확인 가능 (대조군보다 얼마나 더 많은 action을 하는가)
Reference
- A/B Test 신뢰할 수 있는 온라인 종합 대조 실험
- 경험법칙 (도구변수) : https://arxiv.org/pdf/1902.07133
- 네트워크 ego 중심 랜덤화 : https://arxiv.org/pdf/1903.08755
- 간섭으로 인한 편향은 treatment 효과의 30% 이상 발생한 연구
- Reducing Interference Bias in Online Marketplace Pricing Experiments
- 2sls : 인과추론의 데이터과학 도구변수 설명
- 지리 랜덤화 (Lyft 사례)
- 네트워크 클러스터 랜덤화 (Linkedin 사례)
- 스위치백 (doordash 사례)
728x90
반응형
'Data Analysis & ML > 인과추론' 카테고리의 다른 글
| [인과추론] A/B Test 설계와 결과 검증 (0) | 2025.01.30 |
|---|---|
| [인과추론] 인과추론의 기본개념 (0) | 2025.01.29 |
| [인과추론] A/B Test와 지표(목표지표, 동인지표, 가드레일지표, 종합 평가 기준 (OEC)) (1) | 2024.04.21 |
| [인과추론] Structural Causal Model(SCMs) (구조적 인과모형) (0) | 2023.12.03 |
| [Matching][매칭] PSM(Propensity Score Matching) (PSMPY) (1) | 2022.11.20 |