KoNLPy(코엔엘파이)
- 한국어 처리(텍스트 마이닝)를 위한 Python 패키지
- http://KoNLPy.org/ko/latest/
KoNLPy 설치방법
- Java설치
- https://www.oracle.com/java/technologies/javase-downloads.html
- OS에 맞게 다운로드 한다.
- 환경변수 설정
JAVA_HOME: 설치 경로 지정Path:설치경로\bin경로 지정
- JPype1 설치
- 파이썬에서 자바 모듈을 호출하기 위한 연동 패키지
- 설치:
!pip install JPype1
- KoNLPy 설치
- pip install konlpy
KoNLPy 제공 말뭉치
- kolaw: 대한민국 헌법 말뭉치
- constitution.txt
- kobill: 대한민국 국회 의안(국회에서 심의하는 안건-법률, 예산등) 말뭉치
-1809890.txt ~ 1809899.txt
from konlpy.corpus import kolaw, kobill
print(kolaw.open('constitution.txt').read())KoNLPy 제공 형태소 분석기/사전
- 형태소 사전을 내장하고 있으며 형태소 분석 함수들을 제공하는 모듈
- Hannanum(한나눔)
- KAIST Semantic Web Research Center 에서 개발
- http://semanticweb.kaist.ac.kr/hannanum/
- Kkma(꼬꼬마)
- 서울대학교 IDS(Intelligent Data Systems) 연구실 개발.
- http://kkma.snu.ac.kr/
- Komoran(코모란)
- Shineware에서 개발.
- 오픈소스버전과 유료버전이 있음
- https://github.com/shin285/KOMORAN
- Mecab(메카브)
- 일본어용 형태소 분석기를 한국에서 사용할 수 있도록 수정
- windows에서는 설치가 안됨
- https://bitbucket.org/eunjeon/mecab-ko
- Open Korean Text
형태소 분석기 공통 메소드
morphs(string): 형태소 단위로 토큰화(tokenize)nouns(string): 명사만 추출하여 토큰화(tokenize)pos(string): 품사 부착- 형태소 분석기 마다 사용하는 품사태그가 다르다.
tagset: 형태소 분석기가 사용하는 품사태그 설명하는 속성.
Open Korean Text(OKT)
txt = "전세 낀 매물의 매매계약 단계에서 현 세입자의 동의가 있으면 새 집주인(매수인)도 실거주할 수 있다는 유권 해석이 나왔다. 매수인은 소유권이전등기 전까진 세입자가 계약갱신청구권을 행사하거나 이를 거절할 수 있는 대상은 아니지만, 매매계약의 안정성을 보장하기 위해 이를 허용한다는 취지다."from konlpy.tag import Okt
# Open Korea Text 형태소 분석기
okt = Okt()
# 형태소 추출
okt_tokens = okt.morphs(txt)
len(okt_tokens)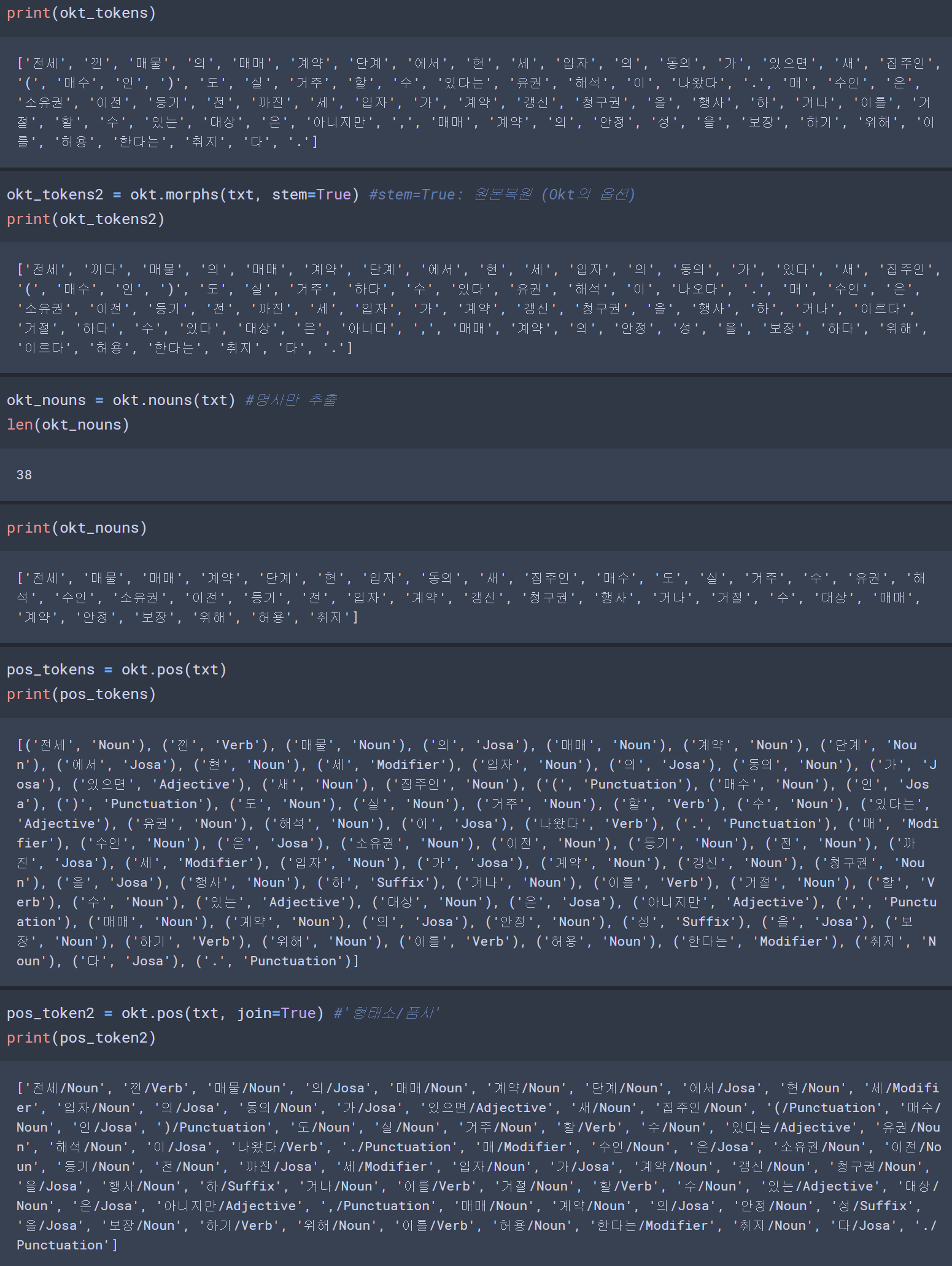
txt = "이것도 되나욬ㅋㅋㅋㅋ"
okt.morphs(txt)
# ['이', '것', '도', '되나욬', 'ㅋㅋㅋㅋ']okt.morphs(txt, norm=True) #norm=True : SNS상의 비속어들을 처리해준다. (OKT의 기능)
# ['이', '것', '도', '되나요', 'ㅋㅋㅋ']okt.normalize(txt), okt.normalize('반갑습니당') # OKT의 기능
# ('이것도 되나요ㅋㅋㅋ', '반갑습니다')komoran
txt = "전세 낀 매물의 매매계약 단계에서 현 세입자의 동의가 있으면 새 집주인(매수인)도 실거주할 수 있다는 유권 해석이 나왔다. 매수인은 소유권이전등기 전까진 세입자가 계약갱신청구권을 행사하거나 이를 거절할 수 있는 대상은 아니지만, 매매계약의 안정성을 보장하기 위해 이를 허용한다는 취지다."
from konlpy.tag import Komoran
komoran = Komoran()
ko_tokens = komoran.morphs(txt)
len(ko_tokens) #84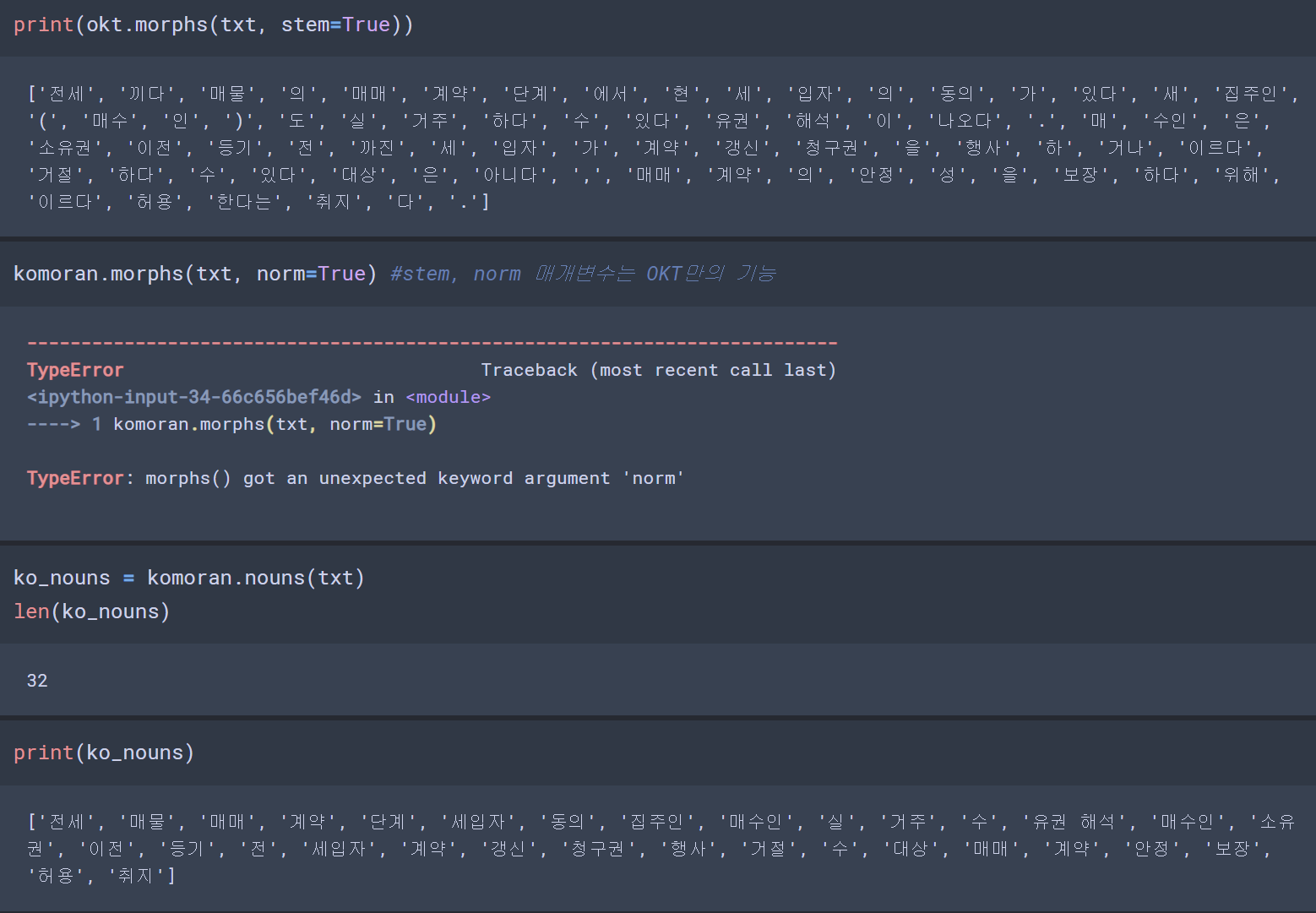
KoNLPy 형태소 분석기와 NLTK를 이용한 문서의 분석
- komoran 사용
from nltk import Text
from konlpy.corpus import kolaw
from konlpy.tag import Komoran
law_txt = kolaw.open('constitution.txt').read() #내장 데이터
# 명사만 추출
komoran = Komoran()
nouns = komoran.nouns(law_txt)
len(nouns) #3358
# 2글자 이상인 단어들만 추출
nouns = [noun for noun in nouns if len(noun)>=2]
len(nouns) #2973
text = Text(nouns, name='대한민국 헌법')
text
print('"대한민국" 빈도수', text.count('대한민국'))
print('"헌법" 빈도수', text.count('헌법'))
print('"국민" 빈도수', text.count('국민'))
# "대한민국" 빈도수 10
# "헌법" 빈도수 55
# "국민" 빈도수 67import matplotlib.pyplot as plt
plt.figure(figsize=(15,10))
plt.title('헌법에 나온 명사 빈도수')
text.plot(20) #빈도수 상위 20개 단어를 선그래프로 그린다.
plt.show()
plt.figure(figsize=(15,7))
text.dispersion_plot(['법률','대통령','국가','국회', '국민'])

# 매개변수로 전달한 단어가 나온 문장 조회
text.concordance('국민', width=50, lines=10) #width-글자수, lines- 라인수
#FreqDist를 이용해 빈도수 관련 정보 확인
fd = text.vocab()
fd
# FreqDist({'법률': 128, '대통령': 84, '국가': 70, '국회': 69, '국민': 67, '헌법': 55, '필요': 30, '기타': 26, '사항': 23, '법관': 22, ...})
print('총 고유단어 개수:', fd.B())
print('총 토큰(단어)의 개수', fd.N())
print('최빈 단어-가장 많이 나온 단어:', fd.max())
print('최빈 단어의 빈도수:', fd.get(fd.max()))
print('총토큰수 대비 최빈단어의 비율:', fd.freq(fd.max()))
# 총 고유단어 개수: 834
# 총 토큰(단어)의 개수 2973
# 최빈 단어-가장 많이 나온 단어: 법률
# 최빈 단어의 빈도수: 128
# 총토큰수 대비 최빈단어의 비율: 0.04305415405314497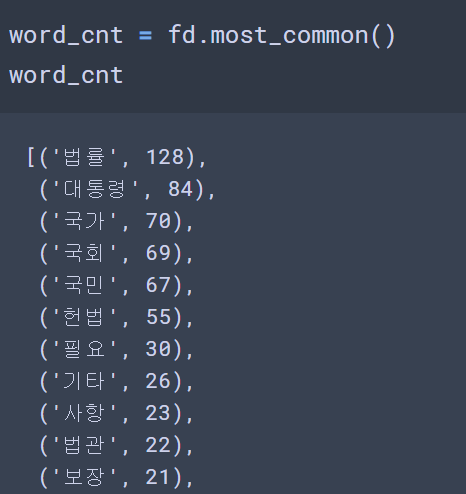
import pandas as pd
law_df = pd.DataFrame(word_cnt, columns=['단어','빈도수'])
law_df.head()
wordcloud
import matplotlib.pyplot as plt
from wordcloud import WordCloud
font = 'c:/Windows/Fonts/malgun.ttf'
wc = WordCloud(
max_words=100,
font_path=font,
min_font_size=1,
max_font_size=50,
relative_scaling = 0.2, # 0 ~ 1, 1: 2배 빈도면 폰트크기가 2배
background_color='white',
# width=600,
# height=400
)
word_cloud = wc.generate_from_frequencies(fd)
plt.figure(figsize=(15,15))
plt.imshow(word_cloud, interpolation='bilinear')
plt.axis('off')
plt.show()

728x90
반응형
'Data Analysis & ML > Text Mining' 카테고리의 다른 글
| [Text Mining]Feature Vectorize(TF-IDF, TfidfVectorizer) (0) | 2020.09.15 |
|---|---|
| [Text Mining] Feature Vectorize (DTM/TDM, CountVectorizer) (0) | 2020.09.15 |
| [Text Mining][NLP] Text Data(텍스트 데이터) 전처리 프로세스 (0) | 2020.09.13 |
| [Text Mining][NLP] NLTK 패키지를 사용한 Text 분석 (형태소, 어간,품사부착,원형복원) (0) | 2020.09.09 |
| [Text Mining][NLP] 자연어 처리를 위한 NLTK (설치 방법 및 사용 문법) (0) | 2020.09.09 |