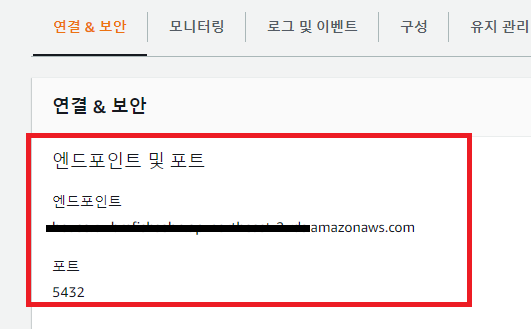
이번 포스팅에서는 이전포스팅에서 만든 아마존 데이터베이스와 PostgreSQL을 연동해보겠습니다. AMS와 PostgreSQL연동하기 먼저 저번에 만든 데이터베이스를 눌러 연결&보안의 엔드포인트를 복사하고 포트번호를 확인합니다.(포트번호는 기본 5432입니다) 이후 PgAdmin에 접속하고, Dashbord의 Add New Server를 눌러줍니다. 먼저 서버이름을 정해주고 Connection탭으로 넘어갑니다. 그리고 복사한 엔드포인트를 Host name/address에 넣고, 아마존 DB를 만들었을때 비밀번호를 넣습니다. 이렇게 하면 연결이 되어야하나..... 대부분 안될겁니다... ㅠㅠ Unable to connect to server: timeout expired aws 이런 오류가 뜰 확률이 높습..