DNN 회귀분석 (DNN Regression)
이번 포스팅에서는 Tensorflow Dataset을 활용하여 DNN으로 회귀분석하는 방법을 알아보겠습니다.
CF) DNN이란 : https://ysyblog.tistory.com/100
Tensorflow Dataset
- 데이터 입력 파이프라인을 위한 패키지
- tf.data 패키지에서 제공
- tf.data.Dataset 추상클래스에서 상속된 여러가지 클래스 객체를 사용 또는 만들어 쓴다.
데이터 입력 파이프라인이란
모델에 공급되는 데이터에 대한 전처리 작업과 공급을 담당한다.
- 이미지 데이터의 경우
- 분산 파일시스템으로 부터 이미지를 모으는 작업,
- 이미지에 노이즈를 주거나 변형하는 작업,
- 배치 학습을 위해 무작위로 데이터를 선택하여 배치데이터를 만드는 작업
- 텍스트 데이터 경우
- 원문을 토큰화하는 작업
- 임베딩하는 작업
- 길이가 다른 데이터를 패딩하여 합치는 작업
Tensorflow Dataset API 사용 방법
- 데이터셋 생성
- from_tensor_slices(), from_generator() 클래스 메소드, tf.data.TFRecordDataset 클래스를 사용해 메모리나 파일에 있는 데이터를 데이터소스로 만든다.
- from_tensor_slices(): 리스트 넘파이배열, 텐서플로 자료형에서 데이터를 생성한다.
- 데이터셋 변형: map(), filter(), batch() 등 메소드를 이용해 데이터 소스를 변형한다.
- for 반복문에서 iterate를 통해 데이터셋 사용
Tensorflow Dataset의 주요 메소드
- map(함수) : dataset의 각 원소들을 함수로 처리한다.
- shuffle(크기): dataset의 원소들의 순서를 섞는다. 크기는 섞는 공간의 크기로 데이터보다 크거나 같으면 완전셔플, 적으면 일부만 가져와서 섞어 완전셔플이 안된다.=>데이터가 너무너무 많으면 적게 주기도 한다.)
- batch(size) : 반복시 제공할 데이터 수. 지정한 batch size만큼 data를 꺼내준다.
import tensorflow as tf
import numpy as np
arr = np.arange(10)
#dataset 객체 생성
dataset = tf.data.Dataset.from_tensor_slices(arr)
print(type(dataset)) # <class 'tensorflow.python.data.ops.dataset_ops.TensorSliceDataset'>
dataset2 = dataset.shuffle(20)
for a in dataset2:
print(a)
dataset3 = dataset.shuffle(20).batch(3) #batch(크기) 한번에 크기만큼 데이터를 제공.
for a in dataset3:
print(a)
epochs = range(3) # epoch->전체 데이터셋을 한번 학습하는 단위.
for epoch in epochs: # epochs=3
print(f'{epoch} 번째 epoch 반복')
for num in dataset.shuffle(10).batch(2):
print(num) #학습 
dataset4 = tf.data.Dataset.from_tensor_slices(arr).repeat(2) #repeat(제공횟수) 지정 횟수만큼 반복해서 값을 제공.
for a in dataset4:
print(a)
DNN 회귀분석 예제 (Boston Housing Dataset)
- 다음과 같은 속성을 바탕으로 해당 타운 주택 가격의 중앙값을 예측하는 문제.
Dataset 구성요소
- CRIM: 범죄율
- ZN: 25,000 평방피트당 주거지역 비율
- INDUS: 비소매 상업지구 비율
- CHAS: 찰스강에 인접해 있는지 여부(인접:1, 아니면:0)
- NOX: 일산화질소 농도(단위: 0.1ppm)
- RM: 주택당 방의 수
- AGE: 1940년 이전에 건설된 주택의 비율
- DIS: 5개의 보스턴 직업고용센터와의 거리(가중 평균)
- RAD: 고속도로 접근성
- TAX: 재산세율
- PTRATIO: 학생/교사 비율
- B: 흑인 비율
- LSTAT: 하위 계층 비율
예측해야하는 것
- MEDV: 타운의 주택가격 중앙값(단위: 1,000달러)
Data Setting
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
# 난수의 시드값 지정
np.random.seed(1)
tf.random.set_seed(1)
# 기본 하이퍼파라미터 지정.
learning_rate = 0.001 #optimizer에 지정할 학습율.
N_EPOCHS = 200 #epoch수 - 전체 데이터셋을 몇번 반복해서 학습할 지.
N_BATCH = 32 #batch_size 지정. - 파라미터를 데이터 몇개당 할 것인지. (mini-batch size)# 데이터 로드
(X_train, y_train), (X_test, y_test) = keras.datasets.boston_housing.load_data()
X_train.shape, y_train.shape, X_test.shape, y_test.shape
# ((404, 13), (404,), (102, 13), (102,))
# Dataset으로 변환. (X,y)를 묶어서 제공.
# drop_reminder매개변수: 남은 짜투리는 버려라.
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))\
.shuffle(500)\
.batch(N_BATCH, drop_remainder=True)\
.repeat() #epoch이 반복되어도 데이터를 계속 공급해야 하기때문에 repeat()을 반드시 한다.
#검증데이터셋.
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(N_BATCH)
DNN Regression 모델링 및 검증
# 모델 생성 - 함수
def create_model():
# 모델생성
model = keras.Sequential()
# 레이어 추가
# units=노드개수
# input layer(input_shape)와 첫번째 hidden layer를 추가.
model.add(keras.layers.Dense(units=16, activation='relu', input_shape=(13,)))
model.add(keras.layers.Dense(units=8, activation='relu'))
model.add(keras.layers.Dense(units=4, activation='relu'))
# output layer: units=1 (회귀), activation=None
model.add(keras.layers.Dense(units=1))
return model# 모델 컴파일 - 설정
model = create_model()
# 회귀의 손실함수(loss) - mse
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='mse')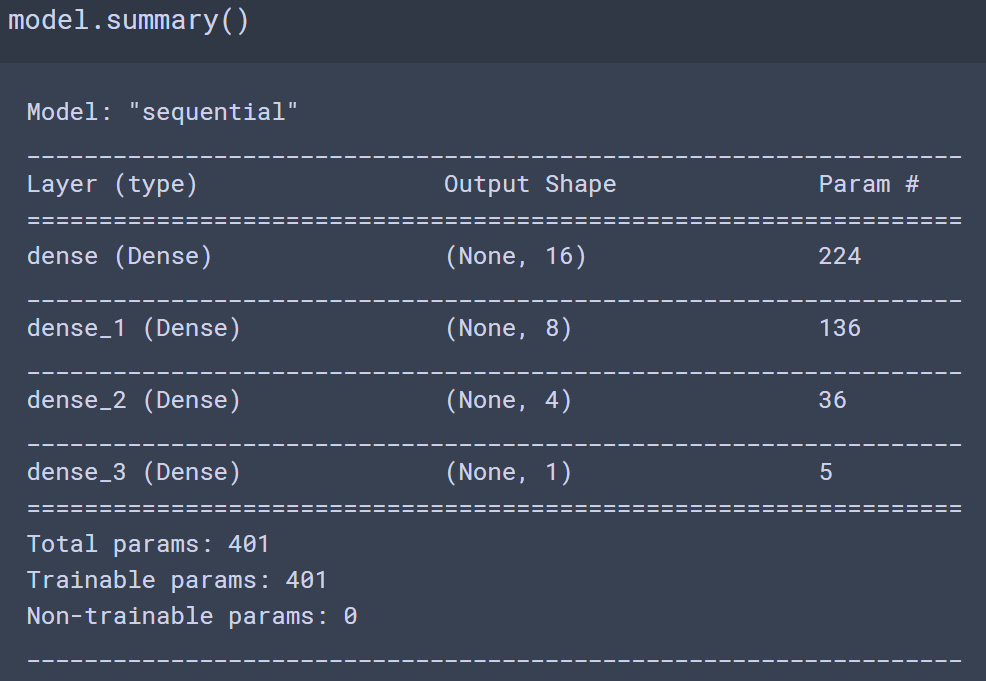
- step(스텝): 파라미터를 한번 업데이트하는 것을 1 step이라고한다.
- steps_per_epoch: epoch 한번에 몇번 파라미터 업데이트(step) 하는 지 지정
- validation_steps: epoch 한번에 몇번 검증을 할 것인지 지정.
#batch 설정시 drop_remainder=True로 했기 때문에 `데이터수/배치사이즈` 에서 몫만 사용.
#(짜투리 때문에)한 번더 업데이트 안하므로.
steps_per_epoch = X_train.shape[0] // N_BATCH
# test_dataset은 drop_remider=False이므로 나머지가 있을 경우 +1을 해야 한다. (한번 더 실행하도록.)
validation_steps = int(np.ceil(X_test.shape[0]/N_BATCH))# 학습
history = model.fit(train_dataset, #학습 데이터셋
epochs=N_EPOCHS,
steps_per_epoch=steps_per_epoch,
validation_data = test_dataset, #검증 데이터셋
validation_steps=validation_steps)
# 테스트셋으로 모델 최종 검증
model.evaluate(test_dataset) # 29.60015296936035
history.history.keys() # dict_keys(['loss', 'val_loss'])# loss 체크
import matplotlib.pyplot as plt
plt.figure(figsize=(10,7))
plt.plot(range(N_EPOCHS), history.history['loss'], label='train loss')
plt.plot(range(N_EPOCHS), history.history['val_loss'], label='validation loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
728x90
반응형
'Data Analysis & ML > Deep Learning' 카테고리의 다른 글
| [Deep Learning][딥러닝] DNN 성능개선 (0) | 2020.11.09 |
|---|---|
| [Deep Learning] DNN 분류 (DNN Classification) (0) | 2020.09.23 |
| [Deep Learning] DNN (Deep Neural Network) (0) | 2020.09.22 |
| [Deep Learning][딥러닝] 딥러닝 구현 (0) | 2020.09.22 |
| [Deep Learning][딥러닝] 딥러닝 개요 (0) | 2020.09.22 |