MNIST 이미지 분류
- MNIST(Modified National Institute of Standards and Technology) database
- 흑백 손글씨 숫자 0-9까지 10개의 범주로 구분해놓은 데이터셋
- 하나의 이미지는 28 * 28 pixel 의 크기
- 6만개의 Train 이미지와 1만개의 Test 이미지로 구성됨.
import tensorflow as tf
from tensorflow import keras
tf.__version__ #'2.1.0'
keras.__version__ #'2.2.4-tf'텐서플로우는 GPU를 사용하는 2.0이상 버전을 설치해야함
# MNIST dataset 조회
(train_image, train_label), (test_image, test_label) = keras.datasets.mnist.load_data()
type(train_image), type(train_label) #(numpy.ndarray, numpy.ndarray)
# 데이터셋의 0번축은 항상 데이터 개수.
# 1축: 높이(height), 2축: 너버(width)
train_image.shape, test_image.shape # ((60000, 28, 28), (10000, 28, 28))
train_label.shape, test_label.shape # ((60000,), (10000,))import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
for idx in range(5):
plt.subplot(1,5, idx+1)
plt.imshow(train_image[idx], cmap='Greys')
plt.axis('off')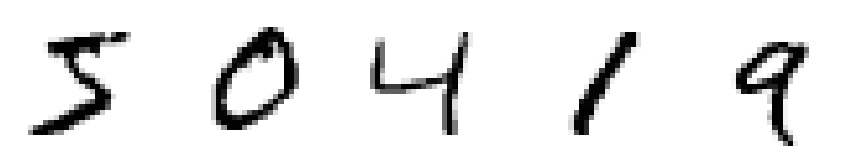
신경망 구현
network : 전체 모델 구조 만들기
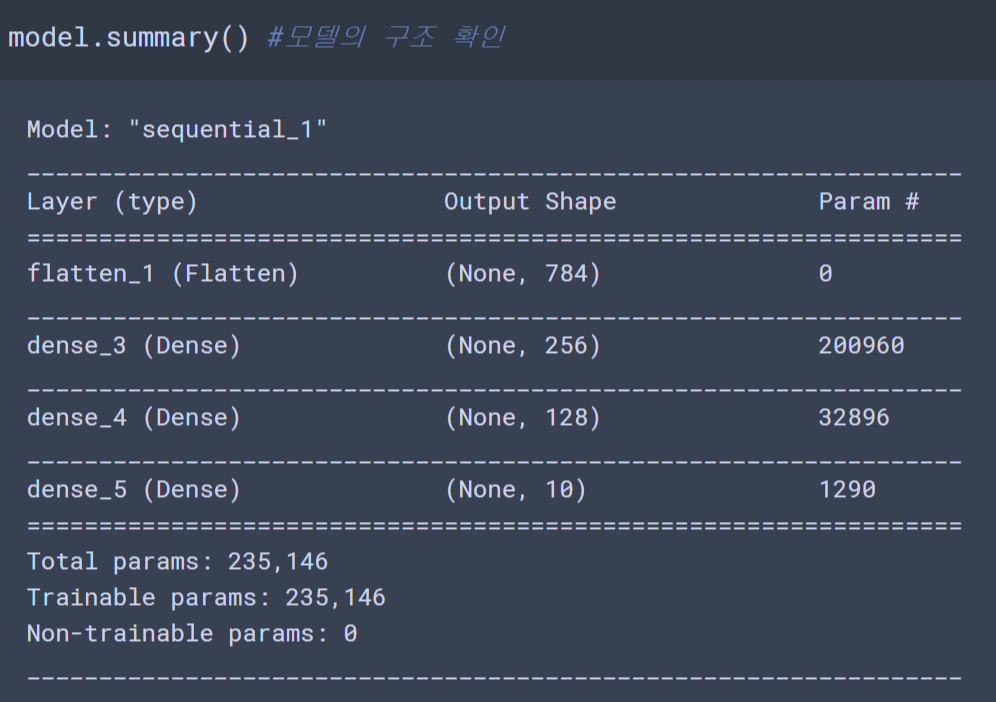
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(256, activation='relu'))
model.add(keras.layers.Dense(128, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))2828256 + 256 = 200960
컴파일 단계
- 구축된 모델에 추가 설정
- 손실함수
- Optimizer(최적화 함수)
- 평가지표
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=['accuracy'])데이터 준비
X
28 by 28 행렬(2D 텐서) 형태의 이미지를 28*28 의 Vector(1d 텐서)로 변환- 0 ~ 1 사이의 값으로 정규화 시킨다.
y
- one hot encoding 처리
- tensorflow.keras 의 to_categorical() 함수 이용
import numpy as np
np.max(train_image), np.min(train_image) #(1.0, 0.0)
# X를 정규화
train_image = train_image/255
test_image = test_image/255
# Y를 one hot encoding
train_label = keras.utils.to_categorical(train_label)
test_label = keras.utils.to_categorical(test_label)
train_label.shape, test_label.shape # ((60000, 10), (10000, 10))학습 (fit)
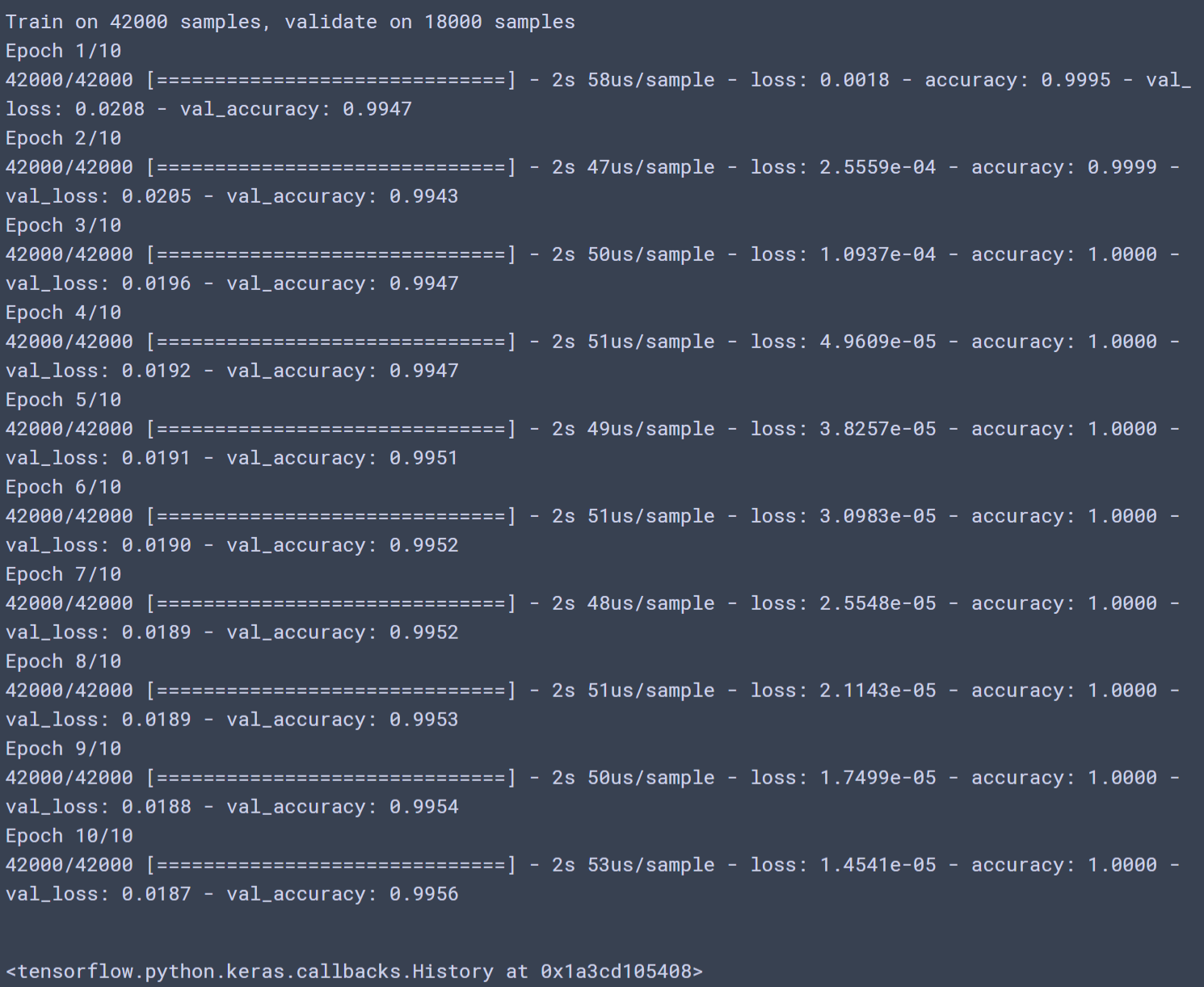
model.fit(train_image, train_label,
epochs=10, #60000개 데이터셋(총데이터셋)을 10번 반복해서 학습시켜라.
validation_split=0.3,
batch_size=100
)
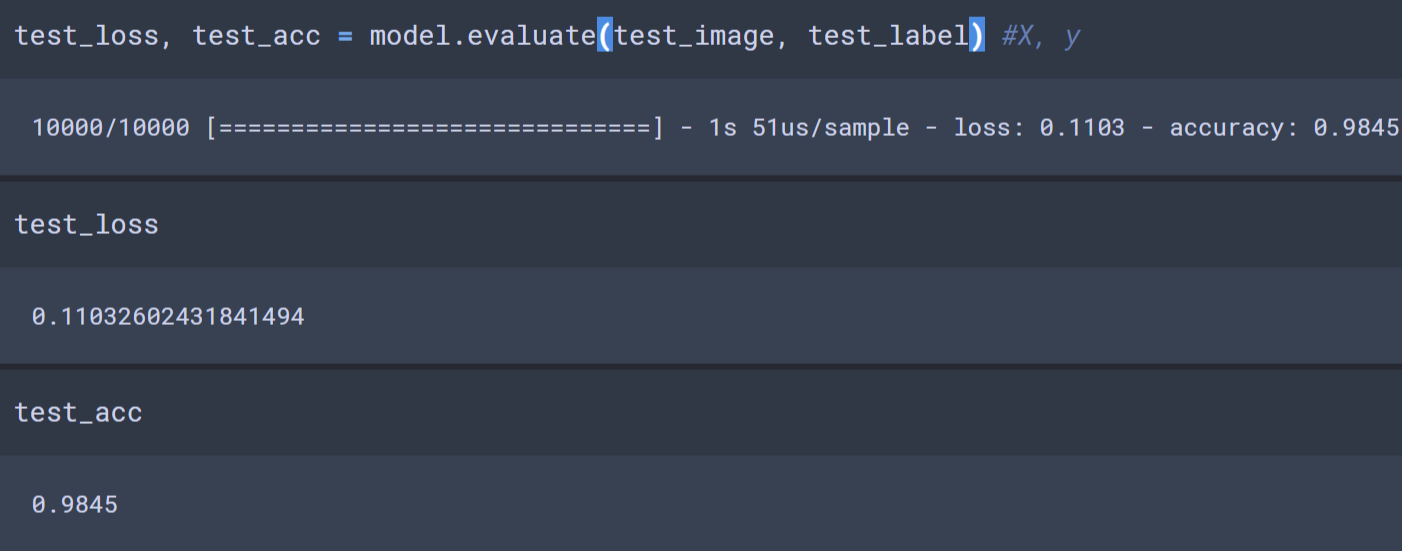
테스트셋 평가
분류
- predict()
- 각 클래스 별 확률 반환
predict_class()- 클래스(범주값) 반환
- tensorflow 2.3 부터 deprecated 됨
- 이진 분류(binary classification)
numpy.argmax(model.predict(x) > 0.5).astype("int32")
- 다중클래스 분류(multi-class classification)
numpy.argmax(model.predict(x), axis=-1)
test_image[0].shape # (28, 28)
test_image[0][np.newaxis,...].shape #(1, 28, 28)
model.predict(test_image[0][np.newaxis,...])
# ==> array([[1.1705486e-19, 4.5926505e-20, 3.4147051e-17, 3.3313310e-17,
4.9706317e-21, 5.3647841e-21, 4.0810197e-27, 1.0000000e+00,
4.5106268e-21, 3.6231668e-10]], dtype=float32)
model.predict_classes(test_image[0][np.newaxis,...])
# array([7], dtype=int64)
728x90
반응형
'Data Analysis & ML > Deep Learning' 카테고리의 다른 글
| [Deep Learning][딥러닝] DNN 성능개선 (0) | 2020.11.09 |
|---|---|
| [Deep Learning] DNN 분류 (DNN Classification) (0) | 2020.09.23 |
| [Deep Learning] DNN 회귀분석 (Tensorflow Dataset) (0) | 2020.09.23 |
| [Deep Learning] DNN (Deep Neural Network) (0) | 2020.09.22 |
| [Deep Learning][딥러닝] 딥러닝 개요 (0) | 2020.09.22 |