회귀모델의 평가지표
지도 학습(Supervised Learning)으로 예측할 Target이 연속형(continuous) 데이터(float)인 경우 회귀분석을 진행하는데 이때 모델을 평가할 때 어떤 지표를 사용하는지 알아본다.
회귀의 주요 평가 지표
회귀분석에 사용하는 평가지표는 예측값과 실제 값간의 차이를 사용하는데, 이를 구하는 방법이 다르다.
- MSE (Mean Squared Error)
- 실제 값과 예측값의 차를 제곱해 평균 낸 것
- mean_squared_error()
- 'neg_mean_squared_error'

- RMSE (Root Mean Squared Error)
- MSE는 오차의 제곱한 값이므로 실제 오차의 평균보다 큰 값이 나온다. MSE의 제곱근이 RMSE이다.
- scikit-learn은 함수를 지원하지 않는다. (MSE를 구한 뒤 np.sqrt()로 제곱근을 구한다.)
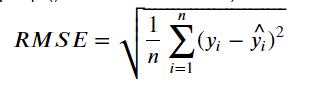
- R^2 (R square, 결정계수)
- 우리가 만든 모델이 데이터를 얼마나 예측하는지에 대한 지표
- 평균으로 예측했을 때 오차(총오차) 보다 모델을 사용했을 때 얼마 만큼 더 좋은 성능을 내는지를 비율로 나타낸 값.
- 1에 가까울 수록 좋은 모델.
- r2_score()
- CF) : https://ysyblog.tistory.com/168


회귀분석 모델링 평가 지표 사용 예시
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
X, y = make_regression(n_samples=100, #샘플수(행수, 관측치개수)
n_features=1, # input data(X) 의 feature(컬럼) 개수
n_informative=1, # target을 예측하는데 영향을 주는 feature의 개수
noise = 50, #잡음(어쩔수 없는-찾을수 없는- 오차.)
random_state=1)
plt.scatter(X, y)
plt.show()
np.mean(y), np.min(y), np.max(y), np.median(y)
(15.293427290684107, -255.11169199137663, 247.19463389209255, 20.62597485010551)
#모델 생성
lr = LinearRegression()
#학습
lr.fit(X, y)
# 예측, 검증
pred = lr.predict(X) #pred=>y_hat#검증(평가)
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y, pred)
rmse = np.sqrt(mse) # mean_abolute_error()
r2 = r2_score(y, pred)
print('MSE:', mse)
print('RMSE:',rmse)
print('R square:', r2)MSE: 2078.5472792307764
RMSE: 45.59108771712709
R square: 0.7321024057172182
# 교차검증
from sklearn.model_selection import cross_val_score
score_list = cross_val_score(lr, X, y, cv=5, scoring='r2')
print("평균 R2", np.mean(score_list))
평균 R2 0.6845162761863837#MSE
score_list = cross_val_score(lr, X, y, cv=5, scoring='neg_mean_squared_error')
# score_list
score_list = score_list * -1
score_list
#==> array([2345.81697166, 1813.79924962, 2204.02751713, 1490.54918087,
3044.11453168])
np.sort(score_list)
#==> array([1490.54918087, 1813.79924962, 2204.02751713, 2345.81697166,
3044.11453168])
print('평균 MSE', np.mean(score_list))
#==> 평균 MSE 2179.661490191461LinearRegression이 학습한 기울기, 절편 조회
# 기울기 : coef_
# 절편 : intercept_
print("기울기:", lr.coef_, "절편:", lr.intercept_)
기울기: [85.14546889] 절편: 10.135071944054275
pred_y = lr.coef_ * X + lr.intercept_
pred_y[:5]
# ==> array([[-41.95321474],[-11.0976856 ],[ 51.73017859],[ 75.01687119],[139.5405874 ]])
pred[:5]
#==> array([-41.95321474, -11.0976856 , 51.73017859, 75.01687119, 139.5405874 ])
plt.figure(figsize=(7,5))
plt.scatter(X, y, label='실제데이터 분포')
plt.plot(X, pred_y, color='red', label='예측선-회귀선')
plt.legend()
plt.show()

머신러닝 회귀 모델 평가 예시
KNN, 결정트리, 랜덤포레스트, GradientBoost 모델링
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, VotingRegressor, GradientBoostingRegressor
knn_reg = KNeighborsRegressor(n_neighbors=3)
tree_reg = DecisionTreeRegressor(max_depth=5)
rf_reg = RandomForestRegressor(n_estimators=50, max_depth=2)
gb_reg = GradientBoostingRegressor(n_estimators=50, max_depth=1)
vote_reg = VotingRegressor(estimators)
estimators = [('knn', knn_reg), ('tree', tree_reg), ('random forest', rf_reg),('gradient boosting', gb_reg),('voting', vote_reg)]회귀 모델 평가
from sklearn.metrics import mean_squared_error, r2_score
def print_metrics(y, pred_y, title):
mse = mean_squared_error(y, pred_y)
rmse = np.sqrt(mse)
r2 = r2_score(y, pred_y)
print(f'{title} - MSE: {np.round(mse,3)}, RMSE: {np.round(rmse,3)}, R square: {np.round(r2,3)}')
for title, model in estimators:
# 학습
model.fit(X, y)
# 예측
pred = model.predict(X)
# 평가
print_metrics(y, pred, title)- knn - MSE: 1363.957, RMSE: 36.932, R square: 0.824
- tree - MSE: 1081.178, RMSE: 32.881, R square: 0.861
- random forest - MSE: 1769.855, RMSE: 42.07, R square: 0.772
- gradient boosting - MSE: 1593.655, RMSE: 39.921, R square: 0.795
- Voting - MSE: 1264.667, RMSE: 35.562, R square: 0.837
DecisionTree 모델링 및 평가, 시각화
tree = DecisionTreeRegressor(max_depth=2)
tree.fit(X, y)
#==> DecisionTreeRegressor(ccp_alpha=0.0, criterion='mse', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
from sklearn.tree import export_graphviz
from graphviz import Source
graph = Source(export_graphviz(tree,
out_file=None,
rounded=True,
filled=True))
graph
728x90
반응형
'Data Analysis & ML > Machine Learning' 카테고리의 다른 글
| [Machine Learning][머신러닝] 군집(Clustering) / K-Means Clustering (0) | 2020.09.07 |
|---|---|
| [Machine Learning][머신러닝] 로지스틱 회귀(Logistic Regression) (1) | 2020.09.07 |
| [Machine Learning][머신러닝][앙상블][부스팅] GradientBoosting (0) | 2020.09.03 |
| [Machine Learning][머신러닝] 최적화 / 경사하강법 (0) | 2020.09.03 |
| [Machine Learning][머신러닝][앙상블] Voting (0) | 2020.09.02 |