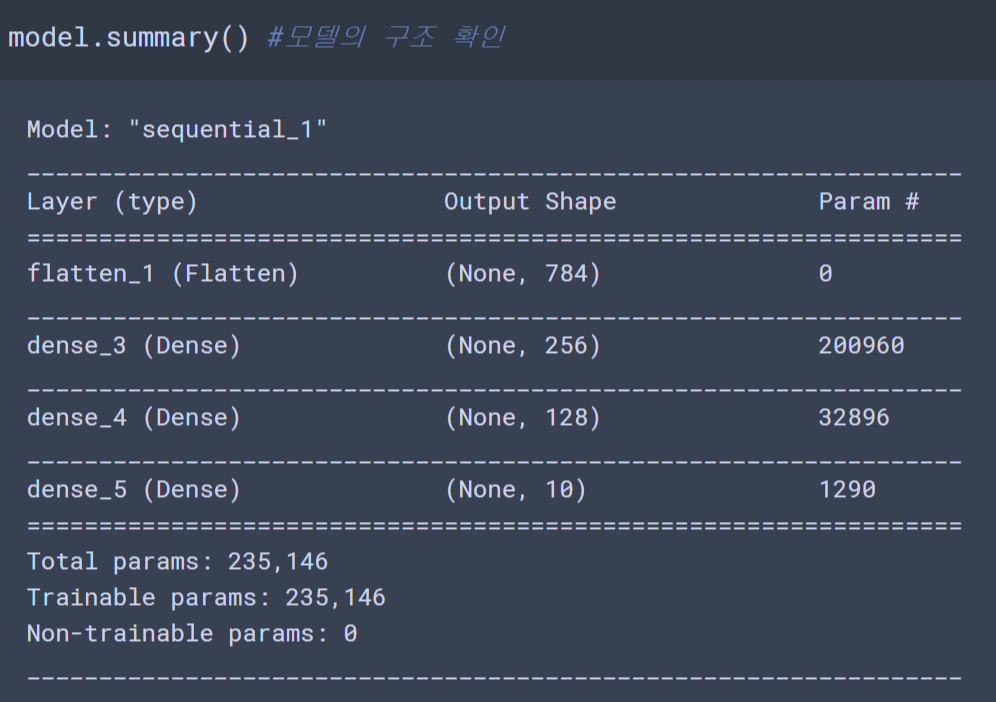
해당 포스팅에서는 Python을 활용하여 표본을 추출하고 T-Test를 진행합니다.표본추출import pandas as pdimport numpy as npfrom sklearn.datasets import load_irisiris = load_iris()df = pd.DataFrame(data=iris.data, columns=iris.feature_names)df['target'] = iris.target층화임의추출모집단이 이일적인 몇개의 계층으로 이루어져있을때 모든계층으로부터 원소를 임읠 추출하여 각 계층을 고루 대표할 수 있도록 랜덤하게 표본을 추출하는 방법from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y..