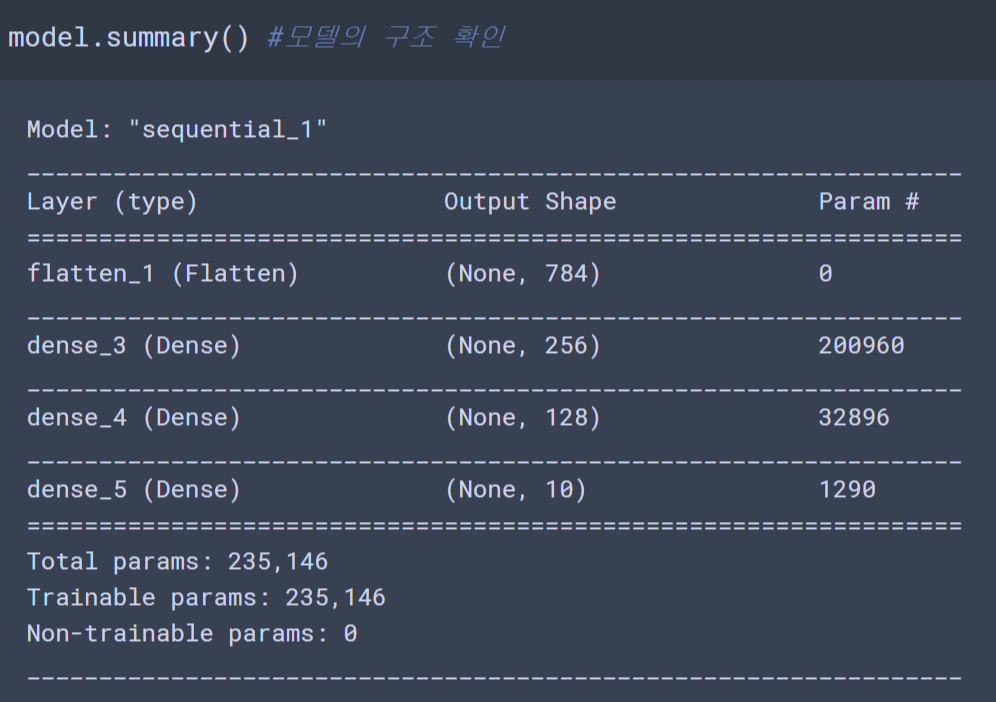
Deep Learning 모델저장 및 Callback모델은 아래 MNIST CNN모델을 활용ysyblog.tistory.com/151?category=1150980 [Deep Learning][딥러닝] CNN MNIST 분류MNIST 데이터에 CNN 적용 하이퍼파라미터 및 데이터셋 전처리 import tensorflow as tf import tensorflow.keras as keras import tensorflow.keras.layers as layers import numpy as np np.random.seed(1) tf.ra..ysyblog.tistory.com 모델 저장딥러닝은 모델을 만드는데 오래걸리기 때문에 이 모델을 따로 저장해 놓을 필요가 있다. 모델을 저장하는 방법은 다음과 같다.학..