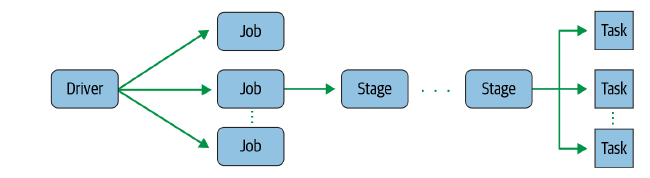
YARN세부 리소스 관리가 가능한 범용 컴퓨팅 프레임웍각 Application (MapReduce, HBase 등) 실행에 필요한 Resource(Cpu, Memory, Disk)를 할당하고 모니터링MapReduce의 단점을 극복하기 위해 하둡 2.0부터 제공CF) MapReduce란 : https://ysyblog.tistory.com/347 [Hadoop] 맵리듀스(MapReduce) Programming맵리듀스 프로그래밍 특징 큰 데이터를 처리할 수 있는데에 목표 데이터 셋의 포맷도 하나로 단순화하였고, 변경 불가 데이터 셋의 포멧은 Key, Value의 집합이며 변경 불가(immutable) 데이터 조작은ysyblog.tistory.com YARN의 구성요소ClusterJob 수행을 위해 여러 대..