[기초통계학] 기댓값 (Expected Value)
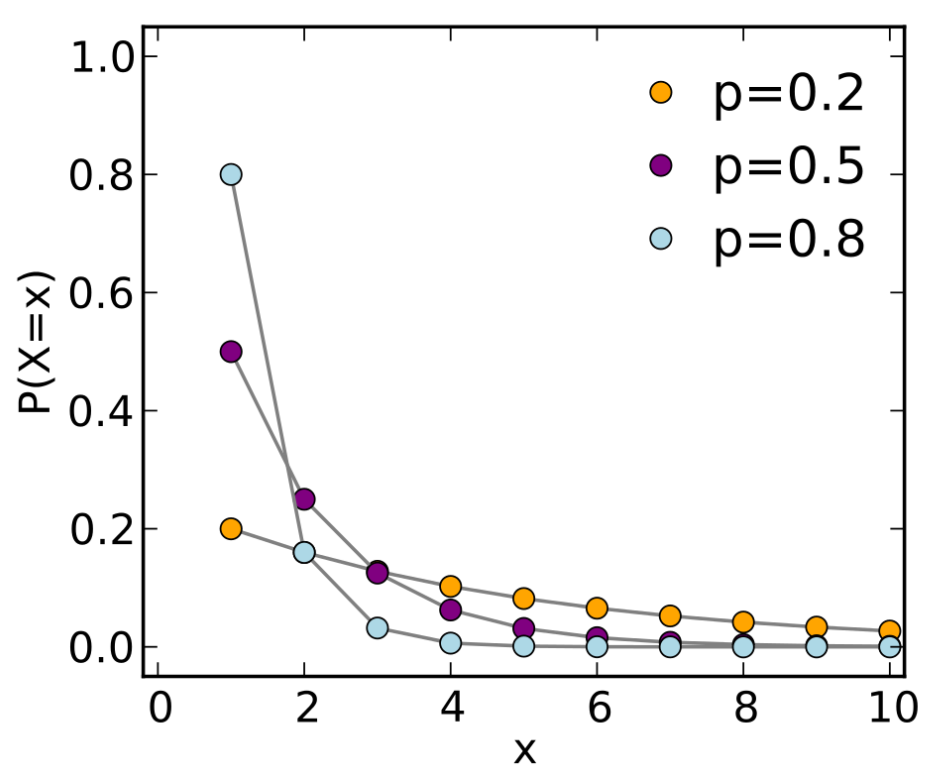
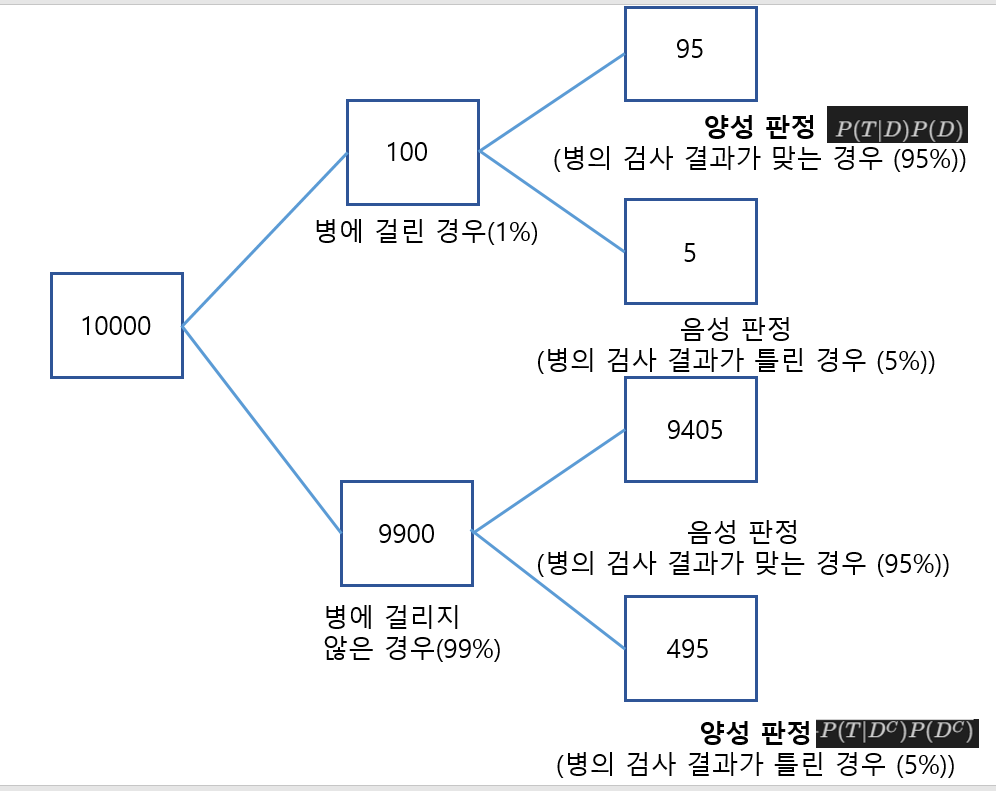
독립 확률변수 (독립성의 정의)모든 x, y 값에 대하여 등식이 성립할 때,확률변수 X, Y가 독립이라고 할 수 있다.이산확률변수의 경우, (※ 연속확률변수에서는 성립하지 않음!)평균(Average, Expected Value)산술평균(전부 더해서 나누기)(unweighted average): 1, 2, 3, 4, 5, 6 → 가중평균(weighted average): 1,1,1,1,1,3,3,5 → $\large \frac {5}{8} \times 1 + \large \frac{2}{8} \times 3+ \l..